Causal Forcing++:少步自回归扩散蒸馏做实时交互视频
Causal Forcing++ 把双向视频扩散蒸馏成 1-2 步逐帧自回归生成器,跑到 14.1 FPS,首帧延迟降一半,少步训练成本砍约 4 倍。
快速答案
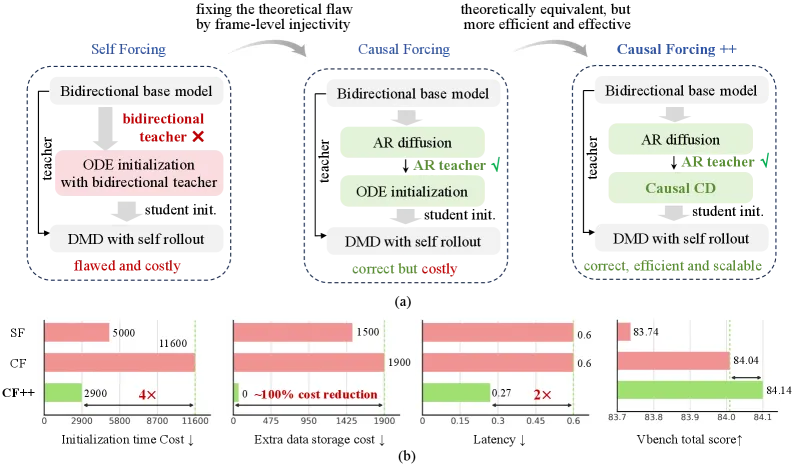
Causal Forcing++ 把一个双向视频扩散模型改造成逐帧自回归生成器,每帧只需 2 步采样,就能以 14.1 FPS 出视频,同时把 VBench 质量保持在接近 4 步基线的水平。在 Wan2.1-1.3B 上,它 2 步时拿到 84.14 的 VBench 总分(对比 4 步 Causal Forcing 基线的 84.04),并把首帧延迟降低 50%(0.27 秒对 0.60 秒)。最亮眼的提速在训练端:少步初始化阶段从 11,600 降到 2,900 A800 GPU 小时,约 4 倍,且不再需要预存任何轨迹。
它在攻克的延迟难题
交互式视频生成——类游戏世界、动作条件模拟器——要求帧能跟着你的操作即时流出,而不是等几分钟。双向扩散模型一次生成整段片段,必须等最后一帧定下来才能开始,这直接扼杀了交互性。自回归(AR)的修法是逐帧生成,但朴素 AR 扩散每帧仍要很多去噪步,实时吞吐依然够不着。早先的 Causal Forcing 把 AR 扩散压到少步,可它的少步初始化用的是因果 ODE 蒸馏,需要在真实视频上预先算出完整去噪轨迹——算力和存储都很贵。
因果一致性蒸馏怎么工作
Causal Forcing++ 的核心取舍,是在少步初始化阶段用因果一致性蒸馏(causal CD)替掉因果 ODE 蒸馏。它不再提前生成并存下完整去噪轨迹,而是在真实视频上、相邻时间步之间取单步在线教师 ODE,把它当作监督信号。论文论证这学到的是与基于轨迹的版本同一个 AR 条件流映射——所以蒸馏目标不变,但信号是即时取得的。这就彻底去掉了预计算环节和那份轨迹存储,约 4 倍的第二阶段省钱正来自于此。
完整配方分三阶段:(1) 用教师强制做多步 AR 扩散训练;(2) 少步初始化,现在改用 causal CD;(3) 学生自滚动的非对称扩散蒸馏,用更大的打分模型(Wan2.1-14B)监督小学生模型。第一和第三阶段在思路上沿用既有蒸馏工作,真正的贡献是让第二阶段变便宜,同时不丢失流映射的等价性。
关键结果
- 吞吐: 2 步逐帧设置跑 14.1 FPS,而 4 步逐帧为 8.69 FPS,4 步分块的 Causal Forcing 基线为 10.4 FPS(均基于 Wan2.1-1.3B)。
- 延迟: 逐帧设置首帧延迟 0.27 秒,分块基线为 0.60 秒——降低 50%。
- VBench: 2 步时总分 84.14、质量 84.89、语义 81.13,对比 4 步 Causal Forcing 基线的 84.04 / 84.59 / 81.84——总体基本持平,质量略高。
- VisionReward: 2 步 6.661、4 步 6.798,都高于分块基线的 6.326。
- 训练成本: 少步初始化阶段从 11,600 降到 2,900 A800 GPU 小时(约 4 倍),零轨迹存储。
老实说:这是一篇效率与工程论文,不是质量跃迁。VBench 总分只动了约 0.1,在噪声范围内,所以价值在于以一半延迟、四分之一的相关训练成本交付接近基线的质量,而不是生成肉眼更好的视频。
局限与存疑
最大的保留是动作条件世界模型那一版仍停留在分块 4 步——真交互模拟最看重的恰恰是这一档,而「完全实时」在这里被推迟了,所以实时这一卖点对提示词驱动生成最站得住脚。尽管做了 AR 训练,曝光偏差仍会让靠后的帧变差,这是自回归滚动的已知失效模式,本文是缓解而非解决。逐帧 1 步设置动态不错但语义理解偏弱,所以现实甜点是 2 步而非 1 步。所有数字都基于 Wan2.1-1.3B 这个小骨干,causal CD 的等价性与训练省钱能否在更大视频模型上成立,这里未做验证。
常见问题
Causal Forcing++ 是什么?
Causal Forcing++ 是一种蒸馏方法,把双向视频扩散模型转成每帧只要 1-2 步采样的逐帧自回归生成器,面向实时交互视频。它建立在 Causal Forcing 这条线上,用因果一致性蒸馏替掉了原本昂贵的少步初始化。
Causal Forcing++ 怎么让视频生成更快?
它逐帧自回归生成,每帧 2 步,在 Wan2.1-1.3B 上达到 14.1 FPS、首帧延迟 0.27 秒,相比 4 步分块基线把延迟砍掉 50%。逐帧设计让首帧在整段片段定稿前就能流出。
为什么因果一致性蒸馏比因果 ODE 蒸馏便宜?
因果 ODE 蒸馏要在训练前于真实视频上预算并存下完整去噪轨迹。因果一致性蒸馏改为取相邻时间步之间的单步在线教师 ODE,学到同一个 AR 条件流映射,却省掉了预计算和轨迹存储——把第二阶段成本从 11,600 降到 2,900 A800 GPU 小时。
Causal Forcing++ 真的比 Causal Forcing 质量更高吗?
并没有明显更高。VBench 总分只动了约 0.1(84.14 对 84.04),在噪声范围内,尽管质量和 VisionReward 略有上升。赢点是用一半延迟、四分之一的少步训练成本追平基线质量,而非更好看的视频。
Causal Forcing++ 用的是什么模型?
主实验用 Wan2.1-1.3B 作学生模型,用更大的 Wan2.1-14B 作打分模型监督第三阶段的非对称蒸馏。
一句话:同样的视频质量、一半的延迟、四分之一的少步训练成本——靠在线蒸馏轨迹而非预计算它。阅读 arXiv 原文。