HRM-Text:1500 美元从零训练 10 亿参数模型
HRM-Text 用约 1500 美元、仅 400 亿 token 从零训出 10 亿参数模型,MMLU 60.7%、GSM8K 84.5%、MATH 56.2%,靠层级循环架构而非堆算力。
快速答案
HRM-Text 是一个 10 亿参数的语言模型,仅用 400 亿 unique token、约 1500 美元(16 张 H100 跑 46 小时)从零训练,MMLU 拿到 60.7%、ARC-C 81.9%、DROP 82.2%、GSM8K 84.5%、MATH 56.2%。它的做法是用层级循环模型(HRM)替换标准 Transformer,并且只在指令-回答对上训练,而非原始网页文本——估计比与之对标的 2-7B 开源模型少用 100-900 倍 token、96-432 倍算力。
为什么 1500 美元预训练才是重点
这篇论文真正的卖点不是”又一个小模型”,而是用任何高校实验室都掏得起的预算,训出了能打的模型。它直击预训练昂贵的两大根源:token 数量和架构的样本效率。标准预训练要烧掉数万亿网页 token,因为在原始文本上做下一词预测本身就是一种很浪费的学习信号。HRM-Text 主张:如果把架构和训练目标一起重新设计,就能把这个量压缩到几百亿 token 而不崩。
作者自己把这项工作定位为”高效预训练的经验性存在性证明”,这是最诚实的解读角度——它证明算力与性能的比值不是定死的,而不是宣称 HRM-Text 打败了前沿模型。
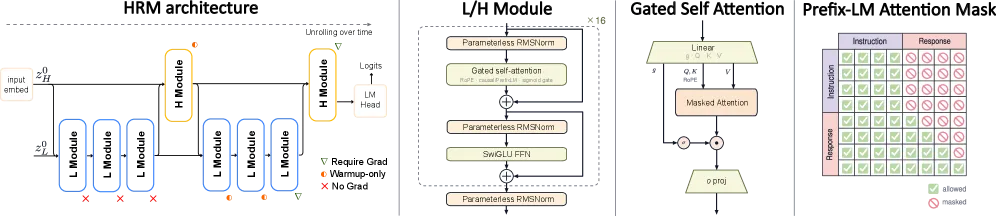
层级循环模型怎么工作
架构灵感来自神经科学,具体是额顶环路的多时间尺度处理。HRM 不再堆叠同样的 Transformer 块,而是把计算拆成两个耦合的循环层:一个慢速演化的策略层,更新频率低、负责保持”计划”;一个快速演化的执行层,每次策略更新内迭代多步。深度来自循环——反复运行同一组层——而非参数量,这就是 10 亿参数模型能获得相当于更大模型”有效深度”的原因。
深度循环对语言建模来说极难稳定训练,论文靠两招压住它:
- MagicNorm:一种归一化方案,利用截断反向传播中前向与反向计算视野的不对称性,把 PreNorm 的恒等通路和 PostNorm 的激活稳定性融合起来。
- Warmup 深度信用分配:把反向传播的视野逐步扩大(从 K=2 步到 K=5 步循环),这种时间课程让信用分配在模型稳定后才逐渐伸向更深处。
为什么只用指令对训练很关键
HRM-Text 从不看原始网页文本。它只在指令-回答对上训练,采用任务完成目标:损失只在回答 token 上计算,不算提示词。它还用 PrefixLM 掩码——指令部分双向注意力、回答部分因果掩码——让一个 decoder-only 模型在指令上表现得像 encoder-decoder。这正是让 400 亿 token 走这么远的杠杆:每一次梯度更新都瞄准一个有用的答案,而不是预测任意网页文本的下一个词。
关键结果
- 10 亿参数 HRM-Text,在 400 亿 unique token 上以 约 1500 美元 训练,取得 MMLU 60.7%、ARC-C 81.9%、DROP 82.2%、GSM8K 84.5%、MATH 56.2%。
- 训练在 16 张 H100 上跑了 46 小时。
- 估计比对标开源模型(Llama 3.2 3B、Gemma 3 4B、OLMo 3 7B,以及 Huginn、Ouro 等循环模型)少用 100-900 倍训练 token、96-432 倍算力。
- 在 10 亿参数规模下,于这些基准上与 2-7B 参数开源模型 表现相当,尽管 token 和算力差距悬殊。
局限与存疑
测试集偏推理和知识(MMLU、GSM8K、MATH、ARC、DROP),而这恰恰是指令对训练和循环”思考”最擅长的地方。论文没有证明 HRM-Text 在开放式生成、长文连贯性、以及原始文本预训练顺带吸收的广博世界知识上能追平 Transformer——所以”与 2-7B 模型相当”应读作”在这些任务上”,而非全面相当。
只用指令-回答对训练也带来一个数据问题:高质量指令数据本身就贵,论文的效率依赖于已有这批数据。算力对比是对不同训练范式下基线的估计,所以 96-432 倍只是指示性区间,不是受控的正面对比。此外,深度循环用串行计算步数换参数量,可能拖慢推理延迟——服务端的成本故事不如训练端清晰。这套配方能否在不引入新不稳定性的前提下扩到 1B 以上,是这份存在性证明留下的问题,而非它回答的问题。
常见问题
HRM-Text 是什么,和 Transformer 有何不同?
HRM-Text 是一个 10 亿参数语言模型,用层级循环模型替换堆叠的 Transformer 块——一个慢速策略层加一个快速执行层,循环多步。深度来自循环而非参数,这让它样本高效到能在 400 亿 token 上训练。
训练 HRM-Text 花了多少钱?
约 1500 美元,对应 16 张 H100 跑 46 小时、400 亿 unique token——比对标的 2-7B 开源模型少用约 96-432 倍算力。
HRM-Text 在基准上表现如何?
10 亿参数模型 MMLU 60.7%、ARC-C 81.9%、DROP 82.2%、GSM8K 84.5%、MATH 56.2%,在这些推理与知识任务上与 2-7B 区间的开源模型表现相当。
HRM-Text 里的 MagicNorm 和 warmup 深度信用分配是什么?
它们是稳定深度循环的技巧。MagicNorm 融合 PreNorm 与 PostNorm 来处理截断反向传播的不对称视野;warmup 深度信用分配在训练中把反传视野从 2 步逐步扩到 5 步循环,让梯度安全地伸向更深。
HRM-Text 预训练用原始网页文本吗?
不用。它只在指令-回答对上训练,损失只算回答部分,并用 PrefixLM 掩码——这是 400 亿 token 就够用的主要原因。
一句话:把循环架构和纯指令目标一起设计,从零预训练就从百万美元问题变成了 1500 美元问题。阅读 arXiv 上的原始论文。