NITP:预测下一个 token 的语义,而非只是它的 ID
NITP 在标准 NTP 之外加了一个稠密的表征监督:让模型预测下一个 token 的浅层表征。9B MoE 上 MMLU-Pro 提升 5.71 分,只多约 2% 训练算力,推理零开销。
快速答案
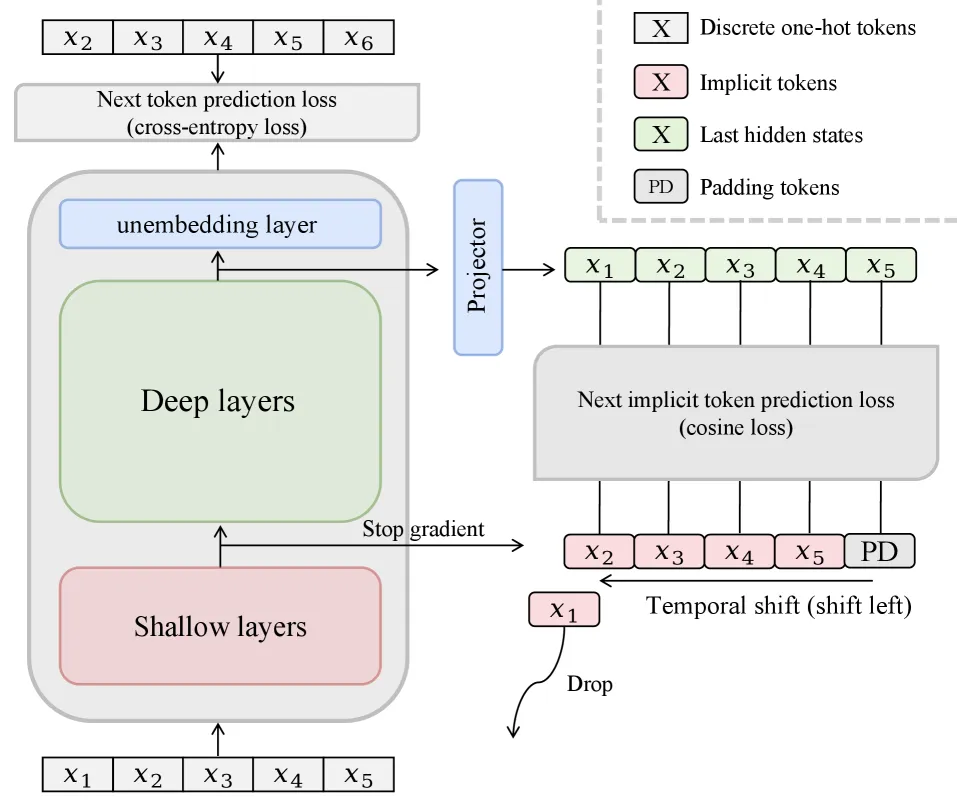
NITP(Next Implicit Token Prediction,下一个隐式 token 预测)在标准的下一个 token 预测(NTP)之外,增加了第二个连续目标:预测下一个 token 的浅层隐藏表征,而不只是它的离散 ID。这个信号是稠密的、自监督的,因此代价只有约 2% 的额外训练 FLOPs,推理零开销。在一个 9B 的混合专家(MoE)模型上,MMLU-Pro 从 15.29 提升到 21.00,绝对提升 5.71 分,13 个基准平均提升 2.67 分。
NITP 要解决的问题
标准 NTP 在每个位置只给模型一个标量监督:正确 token ID 上的交叉熵。这个目标既离散又稀疏。每个位置的完整隐藏状态承载的结构远比一个标签能约束的多,所以表征的大部分几何结构只是被间接塑造。作者认为,这让优化空间约束不足,表征容易塌缩成低秩、表达力差的几何形态。NITP 的思路:在每个位置给模型一个更丰富的连续目标,直接监督表征空间,而不是只在最末端读出。
NITP 怎么做
NITP 不动原来的 NTP 头,而是并联一个”隐式 token”目标。配方有三个关键设计:
- 目标来源——浅层。 预测目标取自模型早期层(约 20% 深度)的隐藏表征,经过 stop-gradient 处理,使其成为稳定的自监督教师而非移动靶。消融显示浅层目标明显优于中层、深层。
- 时间错位——预测的是”下一个” token 的表征。 位置 t 的模型被训练去匹配位置 t+1 的隐式 token,与 NTP 的前瞻一致。改成对齐当前位置则明显变差。
- 损失——余弦相似度。 用尺度无关的余弦损失对齐;作者指出用 MSE 会导致发散。总目标为 L_total = L_NTP + lambda * L_NITP,lambda = 1.0 最优。
由于目标由模型自身的早期激活构造,推理时不需要额外参数,也不需要采集标注数据。
为什么现在值得关注
前沿预训练是算力受限的,因此一个只多约 2% 训练算力、推理零开销就能换来多点基准提升的方法,性价比很突出。NITP 也与多 token 预测等辅助预训练目标同源,但它的目标是连续表征而非额外离散 token——这是在”让 NTP 监督更稠密”这一问题上的另一种杠杆。论文给出的有效秩和余弦几何度量,为”它为何有效”提供了具体证据:表征保持更高秩、结构更好。
关键结果
- 9B MoE(激活 1B): MMLU-Pro 15.29 到 21.00(+5.71),C3 56.65 到 63.01(+6.36),CommonsenseQA 45.70 到 49.96(+4.26),13 个任务平均从 40.27 到 42.94(+2.67)。
- 3B 稠密模型: 七个基准平均提升 1.35 分,C3 +4.66、MMLU +1.41——增益对稠密模型同样成立,不只 MoE。
- 规模覆盖: MoE 从 1.9B 到 45B(激活 0.3B 到 5.5B),稠密模型从 0.5B 到 3B。
- 代价: 约 2% 额外训练 FLOPs,wall-clock 时间几乎不增;推理零开销,因为隐式 token 头训练后即丢弃。
- 几何: NITP 训练出的表征有效秩更高,支撑”稠密目标对抗表征塌缩”的说法。
局限与存疑
论文没有单设局限章节,只能从它测了什么来读边界。最大模型是 45B MoE(激活 5.5B),远低于前沿规模,因此”2% 算力换多点提升”在数千亿参数上是否成立尚未验证。浅层目标、时间错位、余弦损失是消融选出的胜出配置,但 20% 深度这一选择、以及 lambda = 1.0 在差异巨大的架构上的敏感性,并未被穷尽刻画。增益最大的是 MMLU-Pro、C3 这类知识与阅读理解任务,能多大程度迁移到生成质量、长上下文或推理链条,论文没有直接测量。最后,MSE 发散而余弦稳定这一点,暗示方法对目标归一化敏感,部署团队应把它当作调参风险而非免费午餐。
常见问题
NITP 比 NTP 多预测了什么?
NITP 在 NTP 的离散下一个 token ID 之外,额外预测下一个 token 的连续表征——具体是模型自身的浅层隐藏状态,作为 stop-gradient 目标。它是叠加在交叉熵之上的稠密自监督信号,而非替代交叉熵。
NITP 增加多少成本?
约 2% 额外训练 FLOPs,wall-clock 几乎无影响;推理零开销。隐式 token 预测头只在训练时使用,训练后丢弃,部署模型与 NTP 基线运行完全一致。
NITP 只对 MoE 有效,还是稠密模型也行?
都有效。标题结果是 9B MoE(平均 +2.67,MMLU-Pro +5.71),但 3B 稠密模型在七个基准上也平均提升 1.35 分、C3 +4.66,说明该目标不依赖 MoE 的路由机制。
为什么 NITP 用浅层而非深层作为目标?
消融显示浅层目标(约 20% 深度)优于中层、深层。直觉是早期层表征更稳定、更贴近 token,作为自监督教师比已为 NTP 读出而高度特化的后期层更干净。
一句话:给下一个 token 预测配一个稠密目标——下一个 token 的浅层表征——9B MoE 在 MMLU-Pro 上就涨了 5.71 分,只多约 2% 训练算力。阅读 arXiv 原文。