OpenSearch-VL:多模态搜索智能体的开源配方
OpenSearch-VL 开源了数据、代码与权重,训练会调用真实搜索、OCR 和图像工具的视觉语言搜索智能体,30B-A3B 在七个基准上平均比 Qwen3-VL 基座提升 13.8 分。
快速答案
OpenSearch-VL 是一套完全开源的配方——数据集、工具环境、训练代码与权重——用于让视觉语言模型通过「动手做」来答题:在推理途中发起网页与图像搜索、跑 OCR、对图片锐化或裁剪。核心数字是 30B-A3B 模型在七个多模态搜索基准上平均比其 Qwen3-VL 基座提升 13.8 分,作者称在若干任务上已可与 GPT-5、Gemini-2.5-Pro 等闭源模型相当。共发布三个尺寸:8B、30B-A3B(混合专家)和 32B。
真正的问题:能搜索的 VLM 不等于搜索智能体
一个会调用搜索工具的视觉语言模型,在真实多模态问题上依然失败,原因很朴素——长工具链会断。公开的 SFT 轨迹平均每条调用 6.3 次工具,一旦某次搜索返回垃圾、或 OCR 把路牌认错,错误就会级联放大,最终答案崩盘。标准 RL 对每一步一视同仁,所以它学不会从坏的工具结果中恢复。OpenSearch-VL 的整套设计正是冲着这个失败模式去的,而非堆更大的基座。
SearchVL 数据里有什么
配方的第一项资产是数据,且比多数智能体数据集更「工程化」。共发布两套:
- SearchVL-SFT-36k——36,592 条专家轨迹,平均 6.3 次工具调用,在真实工具环境中合成,并用「答案正确性 + 过程级」双裁判做拒绝采样过滤。
- SearchVL-RL-8k——8,000 条与 SFT 不相交的样本,用于强化学习。
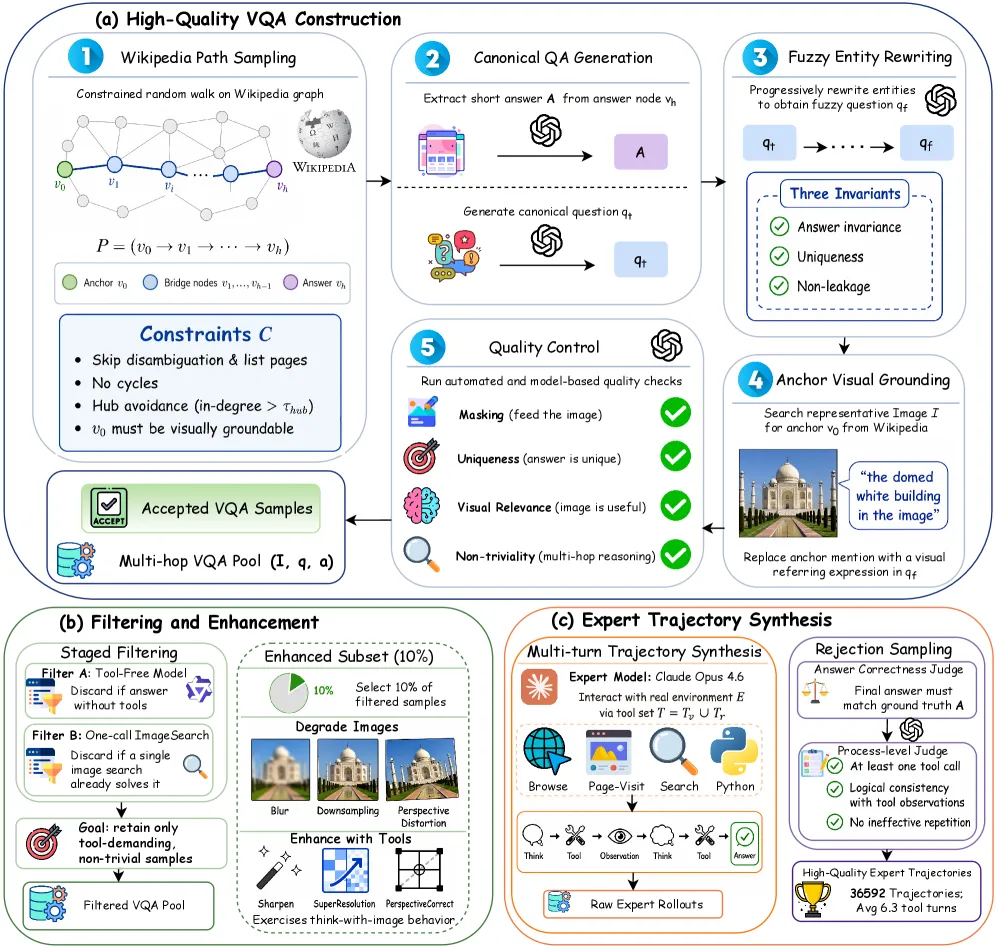
问题取自英文维基百科的超链接图:采样受约束的多跳路径,生成规范问答对,再改写成模糊问题,使模型无法靠记忆作答、必须真正去搜。锚点实体配上代表性图像做接地,分级过滤只保留「需要工具、非平凡」的样本。一个「先退化图像、再用工具复原」的子集刻意训练「看图思考」行为——把图像打模糊,逼模型学会调用 SuperResolution 或 Sharpen。
Fatal-aware GRPO
训练上的贡献是多轮 fatal-aware GRPO。作者把致命步定义为 K=3 次连续工具错误,算法在这些崩盘点附近降权或隔离信用分配,让策略学会恢复,而不是对一条注定失败的回合一律惩罚。在每条样本 K=5 次 rollout、复合奖励(准确率 + 过程质量,权重 α=0.8)下,fatal-aware 变体在 8B 上达到 71.8 分,而原版 GRPO 为 67.6——单凭算法就带来 4.2 分增益。
关键结果
- 30B-A3B:七个基准平均比 Qwen3-VL 基座 +13.8 分;8B 模型比此前 SOTA +3.9 分。
- 各基准(32B / 30B-A3B / 8B): MMSearch 72.3 / 68.7 / 64.5;LiveVQA 70.5 / 67.4 / 59.6;InfoSeek 74.8 / 72.4 / 70.2;SimpleVQA 76.2 / 74.9 / 71.6;FVQA 74.7 / 73.2 / 71.5;BrowseComp-VL 43.8 / 41.1 / 37.6;VDR 33.8 / 33.5 / 20.8。
- 消融显示数据工程才是主力: 去掉源-锚点接地掉 11.5 分,去掉模糊实体改写掉 10.3 分,去掉分级过滤掉 8.2 分。
- 工具套件: 七种工具——TextSearch、ImageSearch、OCR、Sharpen、SuperResolution、PerspectiveCorrect、Crop。
- 成本: SFT 在 256 张 H20 上约 2 天(8B)到 4 天(30B-A3B);RL 在 64 张 H20 上约 200 步、跑 10 天。
诚实判断:这里最大的杠杆是数据构造(模糊改写与接地两项消融各掉 10 分以上),fatal-aware GRPO 贡献真实但更小的 4.2 分。它更像一篇「数据与配方」论文,而非「算法」论文。
局限与存疑
最难的基准暴露了天花板。BrowseComp-VL 只到 43.8、VDR 只到 33.8,远未解决,所以「在若干任务上与闭源模型相当」不应被读成处处持平。问题全部从英文维基百科合成,这既限制了主题与语言覆盖,也有过拟合到单一知识源的风险。工具环境是作者自建的 harness;真实世界的搜索 API 更嘈杂、有限流,线上部署数字可能不同。而那个 +13.8 的头条是相对同系 Qwen3-VL 基座测的——作为消融很公平,但它是配方相对自身起点的增益,而非宣称全面击败最强闭源智能体。
常见问题
OpenSearch-VL 是什么?
OpenSearch-VL 是一套开源配方——SearchVL 数据集、真实工具环境、训练代码,以及 8B / 30B-A3B / 32B 权重——用于训练靠多轮调用搜索、OCR 和图像编辑工具来答题的视觉语言模型。
OpenSearch-VL 比基座提升了多少?
30B-A3B 模型在七个多模态搜索基准上平均比其 Qwen3-VL 基座提升 13.8 分,8B 模型比此前 SOTA 提升 3.9 分。
OpenSearch-VL 里的 fatal-aware GRPO 是什么?
这是一种多轮强化学习算法,它识别「致命步」——连续三次工具错误——并调整信用分配,让智能体学会从断裂的工具链中恢复。在 8B 模型上它比原版 GRPO 多 4.2 分。
OpenSearch-VL 真的开源吗?
是的。作者公开了 SearchVL-SFT-36k 与 SearchVL-RL-8k 数据集、工具环境、训练代码与模型权重,并附有公开的 GitHub 仓库。
一句话:增益主要来自精心合成的搜索数据,fatal-aware GRPO 则教智能体在工具链断裂时活下来。阅读 arXiv 原文。