SAAS:教搜索智能体何时该停手
SAAS 用自我感知强化学习,把 Qwen2.5-7B 搜索智能体的平均检索次数从 2.19 降到 0.97,准确率仍贴近最优基线(48.7% vs 49.8%)。
快速答案
SAAS(Self-Aware Agentic Search)是厦门大学与吉林大学提出的一套强化学习方案,核心目标是让搜索智能体在不需要检索时就别检索。在 Qwen2.5-7B-Instruct 上,它把每个问题的平均检索次数从基线 HiPRAG 的 2.19 次降到 0.97 次,而平均答案准确率维持在 48.7%,与基线的 49.8% 几乎持平。一句话:用大约一半的检索预算,换来几乎相同的准确率。
它针对的问题叫”过度检索”(over-search):智能体明明自己已经知道答案,却还要发起一次检索;或者已经收集到足够证据,却还在继续查。SAAS 让模型学会自己的”知识边界”在哪里,然后只惩罚那些越界的、白费力气的检索。
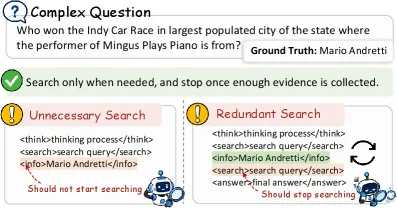
两种过度检索
论文把浪费性检索拆成两类失败模式,整套设计都围绕这个划分展开:
- 不必要检索(unnecessary search):模型的内部参数化知识本来就能答对,它却仍然触发了检索。这是”其实我早就知道”的失败。
- 冗余检索(redundant search):模型已经收集到足够的外部证据,却还在继续发起查询。这是”该收手却不收手”的失败。
两者都只增加延迟与 API 成本,对答案毫无帮助。而像 HiPRAG 这类已经主打效率的方法,在作者的度量里仍然几乎对每个问题都过度检索(问题级过度检索比例高达 100%)。SAAS 有意思的地方在于:它不是简单地对检索次数加一个统一罚项。那样会把模型训得畏首畏尾,在困难的多跳问题上反而掉点。它要找的是每个问题”最小够用”的检索量。
SAAS 怎么做
三个组件叠在一起:
-
搜索边界建模。 对每个训练问题,SAAS 跑两组对照轨迹(一组禁用检索,一组启用检索),以此推断在当前策略下这个问题到底需不需要外部证据。由于 RL 过程中策略一直在变,这个边界是随训练动态重估的,而不是一开始就固定死。
-
边界感知奖励。 把边界信号转化为轨迹级的奖励塑形。对”不必要检索”零容忍(只要在模型本可答对的问题上检索就罚);而对那些确实需要检索的问题,只惩罚超出最小够用阈值的冗余检索。于是奖励能区分”压根不该搜”和”多搜了一次”。
-
分阶段优化。 两阶段课程:先让模型学会推理与检索能力,然后才打开效率正则化。顺序很关键:如果太早就压检索次数,模型会通过”干脆不搜”来钻奖励的空子,把困难题的准确率拖垮。先有能力,再谈节俭。
关键结果
- 检索次数大致砍半。 在 Qwen2.5-7B-Instruct 上,平均检索次数降到 0.97 次/问题,而 HiPRAG 为 2.19 次;在 Qwen2.5-3B-Instruct 上为 1.13 次。作者报告基线普遍需要 1.69 到 2.19 次检索。
- 准确率守住,没被牺牲。 7B 模型平均准确率 48.7%,与 HiPRAG 的 49.8% 仅差约一个百分点——检索预算近乎砍半,准确率几乎不变。
- 过度检索比例骤降。 问题级过度检索比例从 100% 降到 45.9%,步骤级冗余检索比例从 19.5% 降到 6.3%。
- 跨模型成立。 结果在 Qwen2.5-3B-Instruct、Qwen2.5-7B-Instruct、Qwen3-4B-Instruct 上均有报告,覆盖七个问答基准:TriviaQA、PopQA、NQ、HotpotQA、2WikiMultiHopQA、MuSiQue、Bamboogle。
我的判断:准确率的故事是”持平,而非更优”,这恰恰是最诚实的定位。SAAS 并不标榜自己答得更聪明,它标榜的是答得一样好、运行成本却只有一半。对任何按检索次数或按上下文 token 付费的人来说,这才是真正要看的数字。
局限与存疑
- 只测了纯文本证据。 评测局限在单模态文本检索。作者声称框架原则上与模态无关,但图像、表格、结构化数据库都留给了未来工作,所以文本问答之外的效率收益尚未验证。
- 不提升准确率。 SAAS 是拿检索预算换成本,不是换更好的答案。如果你的瓶颈是困难多跳问题的答案质量,这不是对的工具。
- 边界估计有开销。 通过”开搜/关搜”对照轨迹来推断搜索边界会增加训练时开销,而论文的收益是推理效率,不是训练效率。
- 对比范围。 最强对比对象是 HiPRAG;在同一固定检索语料下,SAAS 相对最新前沿 agentic search 系统的差距如何,值得在假设其领先可泛化之前先审视一番。
常见问题
SAAS 相比普通搜索智能体到底减少了什么?
减少的是检索调用次数,而不是答案准确率。在 Qwen2.5-7B-Instruct 上,它把平均检索从 2.19 次降到 0.97 次,问题级过度检索比例从 100% 压到 45.9%,准确率仍维持在 48.7% 左右。
SAAS 和直接惩罚检索次数有什么不同?
统一罚项会让智能体变得畏惧检索,在困难多跳问题上掉点。SAAS 改为对每个问题建模一条知识边界:对不必要检索零容忍,但只对超出最小够用阈值的冗余检索收费,并把训练分阶段,先学会推理能力,再施加效率约束。这样就避免了”干脆不搜”式的奖励钻空子。
想提升问答准确率,该用 SAAS 吗?
不该。SAAS 是效率方法,它让准确率基本持平(7B 上 48.7% vs 基线 49.8%),同时把检索成本砍半。如果你的目标是更好的答案而非更便宜的答案,该另找方案;但如果你按检索次数付费,SAAS 正中要害。