TrOPD:面向小模型的信任域在线策略蒸馏
TrOPD 只在教师真正可信的 token 上做在线策略蒸馏,在数学、代码、STEM 上比标准 OPD 平均高出 3.06 到 3.52 分。
快速答案
TrOPD(信任域在线策略蒸馏)让小学生模型在数学推理、代码生成、STEM 综合基准上的平均分比标准在线策略蒸馏(OPD)高出 3.06 到 3.52 分。它的核心动作很窄:只在教师概率不低于学生概率的 token 上保留 OPD 梯度,其余 token 改用前向 KL 单独处理。实验中的学生模型是 DeepSeek-Qwen2.5-1.5B 和 Qwen3-SFT-1.7B,教师是 Skywork-OR1-7B 系列与 Qwen3-Nemotron-4B。
TrOPD 要修的不稳定问题
在线策略蒸馏让学生用自己采样的轨迹学习,由教师打分。它的崩溃点在于:当学生生成一个教师认为极不可能的 token 时,反向 KL 会产生一个巨大且嘈杂的梯度,把学生推下悬崖而不是纠正它。学生与教师分布偏离越远,这个问题越严重——也就是说 OPD 恰好在推理最依赖的探索性难 token 上失稳。TrOPD 的前提是:教师只在一部分 token 上是可靠监督者,其余 token 不该被无条件信任。
信任域 OPD 怎么工作
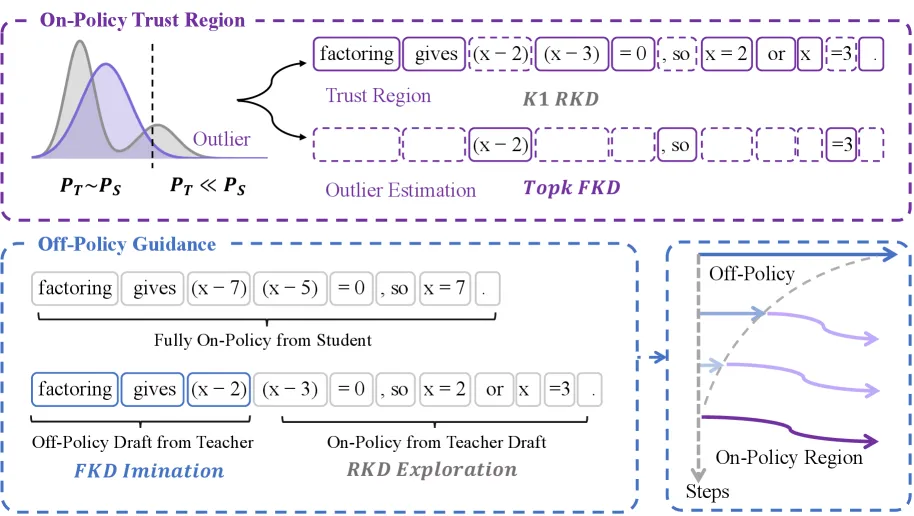
TrOPD 用逐 token 的信任比 P_trust(x) = min(教师概率 / 学生概率, 1) 把每个 token 分成信任域和离群集。
- 信任域在线学习:只在教师给的概率不低于学生的 token 上保留标准 OPD 梯度,因为这里的教师信号可靠。
- 离群估计:在教师认为不可能的 token 上,把不稳定的反向 KL 梯度换成对教师 top-k 词表的前向 KL,既不盲信坏梯度,也不直接把 token 屏蔽成零,而是回收可用的监督信号。
- 离线引导:训练早期让学生从教师写好的前缀继续生成,并用前向 KL 模仿,权重 beta = 0.001 并逐步退火到零,在学生自己的轨迹还不够好之前先做引导。
整套设计是一个信用分配的故事:逐 token 判断教师值不值得主导这一步梯度。
关键结果
- 数学单领域(表 1):TrOPD 平均 49.85,OPD 为 46.79,提升 +3.06;AIME 24 为 38.54(对比 35.83),AIME 25 为 32.50(对比 29.16),AMC 23 为 78.51(对比 75.39)。最强基线 REOPOLD 为 47.86。
- 多领域,DeepSeek-Qwen-1.5B(表 3):TrOPD 平均 40.63,OPD 为 37.11,提升 +3.52;其中 GPQA 提升最大,36.24 对比 28.03。
- 多领域,Qwen3-SFT-1.7B(表 4):TrOPD 平均 51.73,OPD 为 48.29,提升 +3.44。
- TrOPD 在 OPD、EOPD、REOPOLD 三个基线上全面领先。
比单个数字更值得看的是一致性:同样约 3 分的差距在三种设置、两个学生底座、四类基准上都成立,这正是一个稳定性方法该有的表现。
为什么现在重要
在线策略蒸馏正成为把前沿推理能力压进可部署小模型的默认手段,而它最大的实际抱怨就是这种不稳定。TrOPD 没有发明新的损失家族,而是在 OPD 之上加了一个便宜、可解释的”是否信任教师”的门,容易接到现有流水线上。GPQA 上的提升说明,收益最明显的地方正是 OPD 原本最弱的、更难的分布外 token。
局限与存疑
作者把主要局限写为:缺少在小推理模型上的实际部署与应用研究——工作仅停留在后训练阶段,没有预训练或中训练。此外,所有结果都基于 1.5B-1.7B 学生配 4B-7B 教师,这约 3 分的差距在更大学生规模或更大师生差距下能否保持尚未验证。信任比和 beta = 0.001 这些超参看起来是调出来的,文中也没有拆解收益分别来自信任掩码、离群前向 KL 还是离线热身。如果你的 OPD 本来就稳定,预期只是小幅提升;如果瓶颈在教师质量而非梯度噪声,TrOPD 帮不上。
常见问题
什么是信任域在线策略蒸馏 TrOPD?
TrOPD 是一种在线策略蒸馏方法:只在教师概率不低于学生概率的 token 上保留教师梯度,其余离群 token 改用对教师 top-k 词表的前向 KL,从而比标准 OPD 平均高约 3 分。
TrOPD 比标准 OPD 好多少?
TrOPD 在数学单领域上平均提升 +3.06 分,在 DeepSeek-Qwen-1.5B 多领域上提升 +3.52 分,在 Qwen3-SFT-1.7B 上提升 +3.44 分,并在 OPD、EOPD、REOPOLD 上全面领先。
TrOPD 用了哪些学生和教师模型?
学生是 DeepSeek-Qwen2.5-1.5B 和 Qwen3-SFT-1.7B,教师是 Skywork-OR1-Math-7B、Skywork-OR1-7B 和 Qwen3-Nemotron-4B,实验仅在这些小学生上做后训练。
TrOPD 有哪些局限?
TrOPD 只在 1.5B-1.7B 学生配 4B-7B 教师上验证,且仅限后训练、无部署研究。作者把缺少实际部署研究列为主要局限,约 3 分的优势在更大规模上尚未证明。
一句话:只在教师配得上时才信它,在线策略蒸馏就不会在难 token 上爆炸。阅读 arXiv 原文。