当视觉替声音作答:音视频模型的「聪明汉斯」效应
头部视频模型看似在听声音,实则靠画面猜。本文用 THUD 探针拆穿这一捷径,1 万样本的两阶段修复把音频理解平均拉高 28 个百分点。
快速答案
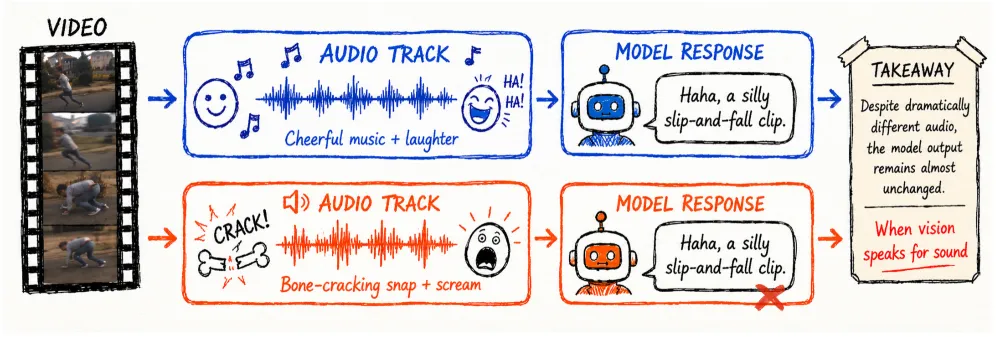
号称「听懂音频」的多模态视频模型,大多是从画面里把声音猜出来的——这就是音视频版的「聪明汉斯」效应。当本文把音轨静音后,模型仍有超过 63% 的概率声称听到了声音,因为它在读画面而非在听声音。作者提出的 THUD 框架用三种反事实音频编辑揭穿这一点,再用约 1 万样本的两阶段修复,把三个探针维度的平均表现拉高 28 个百分点,同时不拖累通用视频成绩。
音视频模型里的「聪明汉斯」问题
聪明汉斯是一匹会「算术」的马,实际上它靠读训练者的肢体语言作答。同样的把戏出现在全模态模型里:问它门有没有被甩上,它只要在画面里看到门关上就能答对,根本没碰音频流。这让标准音视频基准变得有误导性——高分可能意味着强烈的视觉走捷径,而非真在听。本文证明这不是边缘个案:它出现在 Qwen3-Omni、MiniCPM-o、Ming-flash-omni 等开源模型里,也出现在 Gemini、GPT 一类的闭源系统里。
THUD 如何拆穿这条捷径
THUD(时序与幻觉揭示诊断)保持视频不变、只编辑音频,于是任何正确答案都必须来自真正处理声音。它用三种反事实干预:
- Shift(平移):把音频在时间轴上错位,检验模型是否察觉音画不同步,而非默认两者永远对齐。
- Mute(静音):把音轨换成静默,检验模型是否能识别声音缺席,而非从画面里幻想出声音。
- Swap(替换):换上一条不匹配的音轨,检验模型是否抓得到所见与所闻之间的矛盾。
由于三种编辑下视觉证据都不变,一个依赖画面的模型在音频问题上不会比瞎猜更准——而这正是本文观察到的结果。
两阶段修复方案
修复的是训练配方,而非新架构。它以 Qwen3-Omni-30B 为骨干,分两步走:先在干预衍生的数据上做监督微调,再做直接偏好优化(DPO),把反事实的时序偏好对与通用视频偏好混在一起训练。混入通用视频很关键——正是它阻止了模型只对探针过拟合、在普通任务上崩盘。整个过程只用了约 1 万条样本。
关键结果
- 音频理解平均提升 28 个百分点: 用完 1 万样本配方后,THUD 三个维度的平均表现提升 28 分。
- 时序同步(Shift):34.3% 升到 83.1%——单项涨幅最大,说明模型学会了察觉音画错位。
- 分布外泛化:VGGSync 从 36.8% 升到 56.4%,说明修复不只是把域内探针背了下来。
- 静音片段上的音频幻觉修复前超过 63%——这个粗略指标直白地量化了有多少「听」其实是在读画面。
- 通用能力稳住: Video-MME 70.1%、LVBench 52.1%、WorldSense 50.3%、DailyOmni 67.9%——音频修复没有拖累宽泛的视频理解。
一句实话:Shift 这个数字是头条,但它也美化了结果,因为时序对齐是三种行为里最容易用配对数据教会的。Mute 和 Swap——真正的声音存在检测与跨模态一致性——更难,而 28 分的平均把这三者都折进去了。
为什么现在重要
全模态模型当下正以「音频理解」为卖点营销,而本文论证这种能力很大一部分可能是测量假象。THUD 给评测者一种廉价、机械的办法,把真听和视觉猜分开;修复方案则表明这道缺口可以用一个小而精准的数据集补上,而不必从零重训。对任何要交付或采购「会做音频推理」视频模型的人来说,单是静音片段测试就是一个值得一跑的快速体检。
局限与存疑
修复只在单一骨干(Qwen3-Omni-30B)上验证,因此同一套 1 万样本配方能否迁移到其他架构、或迁移到本文诊断过的闭源模型,尚未检验。THUD 的三种编辑是刻意合成的——平移、静音、替换——而现实世界的音频失效可能比干净的反事实更微妙。闭源模型只被诊断、未被修复,因为权重不公开。而且三个维度上的 28 分平均会掩盖不均衡的画像:本文自己的数字显示时序同步涨得远多于更难的一致性行为,所以说「音频理解已解决」会言过其实。
常见问题
《When Vision Speaks for Sound》里的音视频聪明汉斯效应是什么?
它指视频模型看似理解音频,实则从视频画面里推断声音。本文的证据是:在超过 63% 的静音片段上模型仍声称听到了声音——它在读画面,而非读音轨。
THUD 框架如何检验音频理解?
THUD 保持视频不变、只用三种反事实编辑音频——Shift(时间平移)、Mute(换成静默)、Swap(换不匹配音轨)。依赖视觉捷径的模型无法仅凭画面作答,得分因此跌到接近瞎猜。
《When Vision Speaks for Sound》的修复能把音频理解提升多少?
1 万样本的两阶段配方把 THUD 三个维度的平均表现提升 28 个百分点,其中时序同步从 34.3% 跳到 83.1%,而 Video-MME(70.1%)等通用视频基准保持稳定。
哪些模型表现出聪明汉斯效应?
开源模型(Qwen3-Omni、MiniCPM-o、Ming-flash-omni)和 Gemini、GPT 一类的闭源系统都表现出该效应。本文只在开源的 Qwen3-Omni-30B 骨干上完成了修复。
一句话:一个「擅长音频」的视频模型可能只是个高明的读唇者——把片段静音就知道了。阅读 arXiv 原文。