Eywa: Letting LLM Agents Call Scientific Foundation Models
Eywa lets an LLM agent invoke domain models like Chronos and TabPFN through a learned interface instead of serializing data into text. On EywaBench it lifts utility from 0.6154 to 0.6558 while cutting ~30% tokens.
Quick answer
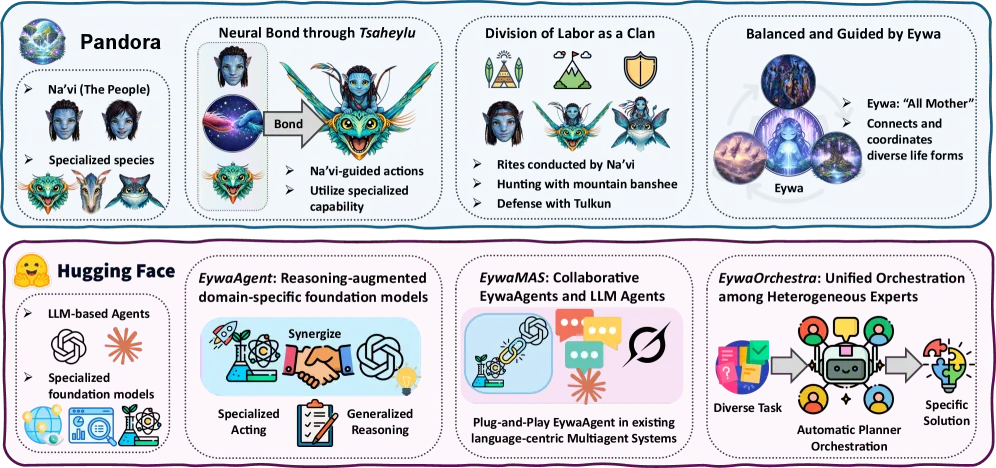
Eywa is a framework that lets a language-model agent hand non-text scientific data — time series, tabular records — to specialized foundation models like Chronos and TabPFN, instead of flattening that data into a prompt and reasoning over the text. On the paper’s EywaBench, the single-agent variant raises overall utility from 0.6154 (a plain LLM agent) to 0.6558, while using about 30% fewer tokens and roughly 10% lower latency. The orchestration variant reaches 0.6746 utility at 8,335 tokens versus the multi-agent version’s 11,214, and 48.16s versus 72.11s inference time.
The problem: language is a lossy interface for science
LLM agents are good at planning and tool use, but they read everything as text. When the real signal lives in a 500-point time series or a wide medical table, serializing it into tokens is both expensive and lossy — the model never sees the data the way a purpose-built forecaster or tabular predictor would. The paper formalizes this as a “language interface bottleneck”: serialization creates an irreducible gap in Bayes risk, which they bound in an information-theoretic argument (the paper’s Proposition 13). The honest framing here is useful — most “LLM + tools” work treats the tool as a black box the model calls; Eywa argues the interface itself is where accuracy leaks.
How Eywa works: the Tsaheylu bond
The core construct is a learned FM–LLM connection the authors name “Tsaheylu” (after the neural bond in Avatar — the whole framework leans on that metaphor, including the Eywa name). It has three parts: a query compiler that turns the LLM’s current state into a configuration the foundation model can run, a response adapter that converts the model’s numeric output back into a language-compatible representation, and a control policy that decides whether calling the specialized model is worth it at all. Foundation models are exposed as remote services via the Model Context Protocol (MCP), so the agent treats Chronos (time series) and TabPFN (tabular) as schema-defined endpoints.
The framework comes in three tiers. EywaAgent augments one LLM with one foundation model. EywaMAS composes several language-only agents and EywaAgents in a fixed topology. EywaOrchestra adds a conductor that picks the agent types, language models, foundation models, and communication topology per task — the automation layer.
Key results
All numbers are on EywaBench, a benchmark the authors build from DeepPrinciple, MMLU-Pro, fev-bench, and TabArena, spanning 9 scientific subdomains across physical, life, and social science, and three modalities (text, time series, tabular), scored on a unified 0–1 utility scale.
- EywaAgent vs. single-LLM agent: overall utility 0.6558 vs. 0.6154, with about 30% fewer tokens and ~10% lower latency.
- EywaMAS vs. homogeneous baselines (Refine, Debate): 0.6761 vs. 0.6294 utility, though at higher token cost (11,214 vs. 8,673).
- EywaOrchestra: 0.6746 utility — nearly matching EywaMAS — but at 8,335 tokens and 48.16s inference, versus EywaMAS’s 11,214 tokens and 72.11s. The automation buys back most of the efficiency the multi-agent setup spent.
- Per-domain (gpt-5-nano): social science reaches 0.7488 utility and physical science 0.6914, while life science sits at 0.5001 — the gains are real but uneven across fields.
- Theory: the paper proves a strict optimal-risk improvement of EywaAgent over a language-only agent (its Theorem 3), under the assumption that domain models beat LLMs on serialized domain inputs.
Why this matters now
Agent frameworks have converged on “LLM orchestrates text tools,” but science runs on numerical and structured data where dedicated foundation models already exist and outperform LLMs. Eywa is one of the cleaner attempts to make those two worlds talk through a principled interface rather than a stringified function call, and it backs the claim with both a theory bound and a cross-domain benchmark rather than a single cherry-picked task.
Limits and open questions
The absolute utilities are modest — 0.6558 vs. 0.6154 is a real but small lift, and life-science utility at 0.5001 shows the approach does not rescue every domain. Dynamic orchestration is limited to a finite pool of fixed topologies, and the conductor is an LLM doing a mapping, not a learned policy, so “automated configuration” is shallower than it sounds. Only two foundation models (Chronos, TabPFN) and two modalities beyond text are actually wired in; scaling to more scientific modalities is left to future work. Results lean on small backbones (gpt-4.1-nano, gpt-5-nano, gpt-5-mini), so it is unclear how the gap behaves with frontier models that serialize numbers better. And the Avatar-themed naming, while memorable, can obscure that the moving parts are a fairly standard compiler/adapter/router stack.
FAQ
What does Eywa actually do differently from normal LLM tool use?
Eywa routes non-text scientific data to specialized foundation models through a learned interface (the “Tsaheylu” bond: query compiler, response adapter, control policy) instead of serializing time series or tables into a text prompt. The argument is that text serialization itself loses information, so the gain comes from preserving the native data format, not just adding another tool.
What benchmark and models does Eywa use?
Eywa is evaluated on EywaBench, built from DeepPrinciple, MMLU-Pro, fev-bench, and TabArena, covering 9 subdomains across physical, life, and social science and three modalities. The integrated foundation models are Chronos for time series and TabPFN for tabular prediction, with gpt-4.1-nano, gpt-5-nano, and gpt-5-mini as LLM backbones.
How much does Eywa improve results?
EywaAgent raises overall EywaBench utility from 0.6154 to 0.6558 over a single-LLM agent while cutting roughly 30% of tokens. EywaOrchestra reaches 0.6746 utility at 8,335 tokens and 48.16s inference, compared with 11,214 tokens and 72.11s for the EywaMAS multi-agent variant.
Is Eywa ready for production scientific work?
Not as a turnkey system. Only two foundation models and two non-text modalities are wired in, the orchestration uses a fixed topology pool with an LLM-mapped conductor rather than a learned policy, and tests use small backbones. It is a research framework with a theory bound and a benchmark, not a deployed scientific platform.
One line: Eywa argues the real loss in “LLM + tools” is the text interface, and shows a learned FM–LLM bond claws back utility and tokens on EywaBench. Read the original paper on arXiv.