Diffusion Models · Efficient AI · World Models
LongLive-2.0: NVFP4 4-bit Training and Inference for Long Video
LongLive-2.0 runs a 5B long-video model end to end in NVFP4 4-bit, hitting 45.7 FPS at 720p, 2.1x faster training and 1.84x faster inference, while VBench total drops only ~0.5 points from BF16.
Quick answer
LongLive-2.0 is the first system to run both training and inference of a long-video diffusion model entirely in NVIDIA’s NVFP4 4-bit format, and it does so without the usual quality collapse. The 5B model reaches 45.7 FPS at 1280x720 in its 2-step setting, trains up to 2.1x faster and infers 1.84x faster than BF16, while its VBench total only slips from 85.06 (BF16) to 84.51 in the 4-step NVFP4 setting — a roughly half-point drop for a 4-bit pipeline.
Why 4-bit long video was the hard case
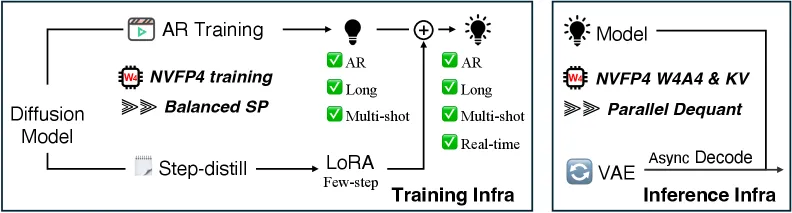
Quantizing inference to 4 bits is now common; quantizing the whole long-video training and inference stack is not. Long video is the worst case for low precision because errors compound: an autoregressive model conditions each new chunk on its own earlier output, so a small per-step rounding error in 4-bit accumulates across a 60-second clip and shows up as drift, flicker, and identity loss. On top of that, training long clips blows past single-GPU memory, so you need sequence parallelism — and naive SP wastes work because clean (already-denoised) and noisy latent chunks are unevenly distributed across ranks. LongLive-2.0’s contribution is making NVFP4 survive both pressures at once.
How Balanced SP and NVFP4 fit together
The training side pairs two ideas. Balanced SP pairs a clean latent chunk with a noisy one on each GPU rank, which keeps the teacher-forcing mask natural and cuts per-rank VAE encoding from O(F) toward O(F/P + h), where F is frames, P the SP degree, and h a small halo. That rebalancing is what turns out-of-memory BF16 runs into trainable ones and gives most of the training speedup. NVFP4 then quantizes weights and activations to the E2M1 4-bit float using hierarchical scaling — FP4 values, FP8 block scales, FP32 tensor scales — so the matmuls run on Blackwell’s 4-bit Tensor Cores. The paper also tunes the diffusion model directly with distribution-matching distillation rather than first initializing from an ODE solver, which keeps the few-step student stable in 4-bit.
Inference: W4A4 plus streaming VAE
At inference the model runs W4A4 (4-bit weights and activations) and adds two memory tricks. KV-cache entries are reshaped and quantized independently with NVFP4 micro-block scaling for about 3.6x KV compression at under 2% overhead, and an asynchronous streaming VAE decodes chunks in parallel with denoising so the decode memory footprint drops from O(C·Tc) toward O(Tc). The combined effect on a GB200 for a 64-second generation is the headline: BF16 needs 112.9 GB and 36.4s, while the 2-step NVFP4 path needs 36.3 GB and runs in 19.4s.
Key results
- Throughput: 45.7 FPS at 1280x720 in the NVFP4 2-step setting; 29.7 FPS for NVFP4 4-step vs 24.8 FPS for BF16 4-step.
- Quality cost: VBench total 85.06 (BF16) to 84.51 (NVFP4 4-step) to 83.14 (NVFP4 2-step); quality sub-score holds at 86.43 vs 86.67.
- Training: a 64-second iteration drops from 1196.5s (BF16 Balanced SP) to 639.5s (NVFP4 Balanced SP), a ~2.1x speedup; plain BF16 without SP runs out of memory.
- Inference memory/latency: 64s generation on GB200 falls from 112.9 GB / 36.4s (BF16) to 36.3 GB / 19.4s (2-step NVFP4), about 1.84x end-to-end.
- KV cache: ~3.6x compression with under 2% overhead; distillation memory is 0.69x of BF16 (49.0 GB vs 70.5 GB).
- Long consistency: on VBench-Long 60s clips, subject consistency stays at 97.48% (BF16) and 97.62% (NVFP4).
Limits and open questions
The speed numbers are hardware-locked. NVFP4 needs NVIDIA Blackwell-class GPUs with native 4-bit Tensor Cores; on A100 or H100 there is no NVFP4 path, and the authors fall back to sequence-parallel inference instead, so anyone not on Blackwell gets the engineering but not the 4-bit acceleration. The quality gap, while small at 4 steps, widens at 2 steps — the fastest 45.7 FPS mode is also where VBench total drops nearly two points and the semantic sub-score falls hardest (76.81 to 74.12), so the headline FPS and the headline quality are not from the same configuration. And as a systems paper its win is throughput and memory, not a new generative capability: the underlying video model is the same family, so this matters most to teams already shipping long-video models on Blackwell hardware and far less to anyone studying generation quality itself.
FAQ
What is LongLive-2.0?
LongLive-2.0 is an NVFP4 4-bit parallel infrastructure from NVIDIA and collaborators that runs the full training and inference workflow of a 5B long-video diffusion model in 4-bit, reaching 45.7 FPS at 720p with about a half-point VBench drop from BF16.
How fast is LongLive-2.0 compared with BF16?
LongLive-2.0 trains up to 2.1x faster (a 64s iteration drops from 1196.5s to 639.5s) and runs inference about 1.84x faster, cutting a 64-second generation on GB200 from 36.4s to 19.4s and from 112.9 GB to 36.3 GB.
Does NVFP4 in LongLive-2.0 hurt video quality?
Only slightly at 4 steps: VBench total goes from 85.06 (BF16) to 84.51 (NVFP4). The faster 2-step mode costs more, dropping to 83.14 total with the semantic score falling from 78.63 to 74.12.
What hardware does LongLive-2.0 require?
The NVFP4 acceleration needs NVIDIA Blackwell GPUs (such as GB200) with 4-bit Tensor Cores. On A100 or H100 there is no native NVFP4 support, so the authors use sequence-parallel inference as the fallback.
One line: NVFP4 4-bit can carry a whole long-video model end to end with almost no quality loss — if you are on Blackwell. Read the original paper on arXiv.