AI Agents · Language Models · Agent Memory
MemPrivacy: Private Edge-Cloud Agent Memory via Reversible Placeholders
MemPrivacy swaps sensitive spans for type-aware placeholders on-device, processes memory in the cloud over them, then restores them locally — utility loss stays within 1.6% and 0.6B-4B models beat GPT-5.2 at detection.
Quick answer
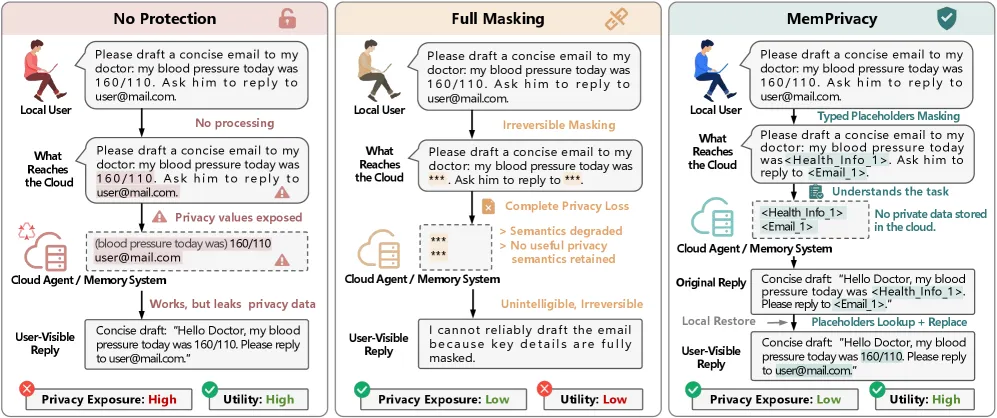
MemPrivacy lets a cloud agent build long-term personalized memory without ever seeing your raw secrets: a small model on the device detects sensitive spans, swaps them for type-aware placeholders, the cloud reasons over the placeholders, and the device restores the real values before showing you anything. Across three production memory systems (LangMem, Mem0, Memobase) this reversible pseudonymization keeps task utility loss within 1.6%, while irreversible masking loses 16.99-41.87%. The team’s purpose-trained 0.6B-4B models hit 85.97% F1 on their own MemPrivacy-Bench and 94.48% on PersonaMem-v2, beating GPT-5.2 and Gemini-3.1-Pro on the same span-detection task.
The privacy gap in agent memory
Personalized agents only get useful by remembering you — your meds, your salary, your home address, your API keys — and that memory increasingly lives in the cloud where the heavy LLM runs. The naive privacy fix is masking: black out anything sensitive before it leaves the device. But masking is lossy and one-way. Once “my blood pressure meds give me dizziness” becomes “[REDACTED] give me [REDACTED]”, the cloud can no longer reason about the medical context, and you can never get the original back. MemPrivacy’s framing is that the real requirement is not deletion but reversibility plus type information: the cloud needs to know it’s handling a medication, a person, or a location to reason correctly, but it does not need the literal value.
How the reversible pipeline works
The method is local reversible pseudonymization in three stages. First, an on-device detector finds privacy spans and replaces each with a placeholder that carries its semantic type — a drug name becomes a typed drug placeholder, not a generic blank. Second, the cloud agent and its memory system operate entirely on the placeholdered text, so plaintext secrets never leave the device. Third, the device holds the mapping and restores the real values locally before presenting results to the user. Keeping the type is what preserves utility: the cloud still knows the structure of the sentence, just not the identity inside it.
Sensitivity is graded with a four-level taxonomy. PL1 is generic preferences (treated as non-sensitive and excluded). PL2 is directly or indirectly identifying information. PL3 is harm-based data such as health, financial, and biometric details. PL4 is immediately exploitable credentials like passwords, tokens, and keys. This lets you tune how aggressively to protect: full PL2-PL4 protection trades a little more utility, while protecting PL4 alone is nearly free.
What MemPrivacy-Bench contains
The authors built MemPrivacy-Bench because no existing benchmark covered graded, reversible memory privacy. It spans 200 users and over 52,000 privacy instances across roughly 1M dialogue tokens, split evenly between Chinese and English. The training split is 26,016 turns from 160 users (125k+ privacy instances); the test split is 6,337 turns from 40 users (29.9k instances). Human verification put annotation accuracy at 98.08%. On top of this they trained six MemPrivacy detector models from 0.6B to 4B parameters using supervised fine-tuning followed by GRPO reinforcement learning with F1 as the reward signal.
Key results
- Utility loss within 1.6%. Full PL2-PL4 protection costs 0.71-1.60% task utility across LangMem, Mem0, and Memobase; protecting only PL4 costs 0.08-0.33%.
- Reversibility beats masking by a wide margin. Irreversible masking loses 16.99-41.87% utility on the same systems, and untyped placeholders still lose 4.72-8.71% — the type information is doing real work.
- Small specialized models beat frontier general models at detection. On MemPrivacy-Bench the best MemPrivacy model reaches 85.97% F1 — +16.98% over GPT-5.2 and +7.56% over Gemini-3.1-Pro. On PersonaMem-v2 it hits 94.48% F1 (+6.42% vs GPT-5.2, +7.89% vs Gemini-3.1-Pro).
- A weak baseline for context. The OpenAI-Privacy-Filter baseline manages only 35.50% F1 on MemPrivacy-Bench, showing off-the-shelf filters are not close.
- Latency stays low. The on-device detector runs in roughly 2 seconds on MemPrivacy-Bench and under 1 second on PersonaMem-v2.
Why a 0.6B model winning matters
The most useful result here is not the headline F1 — it’s that a 0.6B-4B model fine-tuned for one narrow task (typed privacy span detection) beats GPT-5.2 and Gemini-3.1-Pro at it. That is exactly the shape an edge deployment needs: the privacy-critical step has to run locally, and you cannot fit a frontier model on a phone. By showing a small specialist clears the bar, MemPrivacy makes the whole edge-cloud split practical rather than aspirational. The reversibility framing is also the right correction to the masking reflex — for agent memory you almost always want the value back later, so destroying it was always the wrong default.
Limits and open questions
The privacy guarantee is only as strong as the detector’s recall: anything the on-device model fails to tag as sensitive leaves the device in plaintext, and an 85.97% F1 means real misses on hard or novel sensitive spans. The benchmark is the authors’ own and human-annotated to 98.08% accuracy, so the comparison numbers against GPT-5.2 and Gemini-3.1-Pro are not yet third-party reproduced. Typed placeholders reduce but do not eliminate leakage — the cloud still learns the structure and types of your private data, which can be informative on its own. And the threat model assumes an honest-but-curious cloud; it does not defend against a cloud that actively tries to invert placeholders using auxiliary information. Whether the under-1.6% utility figure holds on richer multi-turn agent tasks beyond these three memory libraries is still open.
FAQ
What problem does MemPrivacy solve?
It lets an edge-cloud agent keep useful long-term memory of a user without sending raw sensitive data to the cloud. The device pseudonymizes secrets into typed placeholders, the cloud reasons over those, and the device restores the real values locally.
How is MemPrivacy different from just masking sensitive data?
Masking is irreversible and drops semantic type, costing 16.99-41.87% utility on the tested memory systems. MemPrivacy uses reversible, type-aware placeholders, so the cloud still understands sentence structure and the user can recover the original value — keeping utility loss within 1.6%.
Does MemPrivacy really beat GPT-5.2 and Gemini-3.1-Pro?
At privacy span detection, yes. Its 0.6B-4B models reach 85.97% F1 on MemPrivacy-Bench (+16.98% over GPT-5.2, +7.56% over Gemini-3.1-Pro) and 94.48% on PersonaMem-v2. This is a narrow specialized task, not general capability.
What is MemPrivacy-Bench?
A benchmark of 200 users and 52,000+ privacy instances across ~1M bilingual (Chinese/English) dialogue tokens, with a four-level PL1-PL4 sensitivity taxonomy and 98.08% human-verified annotation accuracy.
Is MemPrivacy safe to rely on for credentials?
Protecting only PL4 credentials (passwords, tokens, keys) costs just 0.08-0.33% utility, so it is cheap to enable. But protection depends on detector recall — any credential the local model misses still leaves the device, so it should be one layer, not the only one.
One line: don’t delete the secret, pseudonymize it locally with its type and put it back later. Read the original paper on arXiv.