Multimodal Models · Text Embeddings
MulTaBench: A 40-Dataset Benchmark for Multimodal Tabular Learning
MulTaBench is a 40-dataset benchmark (20 image-tabular, 20 text-tabular) where each task needs both the table and the image or text. Its finding: tuning embeddings to the target beats frozen embeddings on every learner.
Quick answer
MulTaBench is a benchmark of 40 datasets, split 20 image-tabular and 20 text-tabular, built so that each task genuinely needs both the structured table and the unstructured text or image to be solved well. Its central result is that target-aware embeddings — embeddings fine-tuned on the prediction target — consistently beat frozen pretrained embeddings across every tabular learner the authors tried, to the point that small tuned embeddings outperform large frozen ones. On the PetFinder dataset, for example, LightGBM rises from 77.2% (image only) to 85.7% once both modalities are combined with target-aware representations, and TabPFN-2.5 goes from 81.1% to 88.0%.
Why most “multimodal tabular” benchmarks are not multimodal
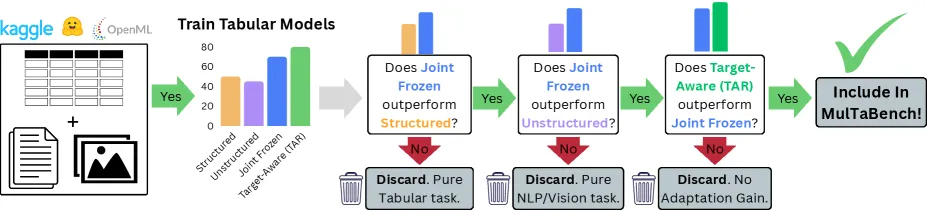
The honest contribution here is the filtering, not the headline metric. Plenty of datasets pair a table with an image or a text field, but in many of them the table alone already contains the signal — the text is decorative. MulTaBench imposes two screens. A joint signal criterion requires that using both modalities actually beats using either one alone; roughly 23% of candidate text-tabular datasets failed this. A task-awareness criterion drops datasets where a generic frozen embedding already captures everything useful; 36% of the remaining datasets failed this. Out of 56 unique text-tabular candidates pulled from existing benchmarks, only 41% passed both screens. Image-tabular was harder still, with about 31% acceptance from the literature before manual curation filled out the final 20.
That filtering is the point. A benchmark where the extra modality does not matter teaches nothing about multimodal fusion, and the field is full of those.
Target-aware vs frozen embeddings
The core experiment compares two ways of turning text and images into features a tabular model can use. The frozen route runs a pretrained encoder — e5 for text, DINO-v3 for images — and feeds its fixed output (reduced by PCA to ~30 dimensions) into the tabular learner. The target-aware representation (TAR) route instead fine-tunes the encoder on the prediction target before extracting features.
TAR wins consistently. The gain shows up across all five primary learners (LightGBM, CatBoost, TabM, TabPFNv2, TabPFN-2.5) and across both modalities, and it generalizes to learners that were not used during curation. The sharpest version of the claim: a TAR variant built on the small embedding model outperformed the large frozen embedding. Scaling the encoder up helps, but it does not close the gap — tuning the representation to the task matters more than encoder size.
What the datasets look like
The 40 datasets span healthcare, e-commerce and other domains, with row counts from about 400 to 114,000 and structured feature counts from 1 to 245 columns. Classification and regression are balanced. Encoders are standardized: e5-v2-small (384-dim) and e5-large (1024-dim) for text, DINO-v3-small (384-dim) and DINO-v3-large (1024-dim) for images, with PCA to 30 dimensions as the default. Beyond the five curation learners, the authors stress-test with XGBoost, RandomForest, RealMLP, TabDPT, TabICLv2, TabSTAR, ConTextTab and AutoGluon-Multimodal, which is what lets them argue the TAR advantage is not an artifact of one model family.
Key results
- 40 datasets total, split exactly 20 image-tabular and 20 text-tabular, balanced between classification and regression.
- Target-aware beats frozen across all five primary learners and both modalities, and the effect transfers to unseen learners.
- Small tuned beats large frozen: a TAR variant on the small encoder outperformed a frozen large encoder, so representation tuning matters more than encoder scale.
- PetFinder, LightGBM: 77.2% (image only) → 85.7% (both modalities + TAR).
- PetFinder, TabPFN-2.5: 81.1% (image only) → 88.0% (both modalities + TAR).
- Curation is strict: of 56 text-tabular candidates only 41% passed; ~23% failed the joint-signal screen and 36% of the remainder failed task-awareness.
Limits and open questions
The authors are unusually candid about the central flaw: the curation pipeline uses tabular models to decide which datasets qualify, so the selection criterion is entangled with the solution being evaluated. That introduces a bias — the curation models themselves cannot be fairly scored on this benchmark, and it is hard to predict in advance which datasets will be eligible. Fine-tuning encoders for TAR also adds significant compute over the frozen route, which the paper relegates to an appendix; for practitioners that cost is the real question, and the headline accuracy gains have to be weighed against it. A narrower concern: when a single e5 model is fine-tuned jointly across multiple text columns, the shared representation can degrade rather than help. And no hyperparameter optimization was run for the curation models, so the screening thresholds are not tuned. None of this sinks the benchmark, but it means the “tune your embeddings” advice comes with a compute asterisk and a curation caveat.
FAQ
What is MulTaBench?
MulTaBench is a 40-dataset benchmark for multimodal tabular learning, evenly split into 20 image-tabular and 20 text-tabular tasks. Each dataset is screened so that both the table and the image or text are genuinely needed, making it a test of fusion rather than of tables that happen to ship with an image.
What is the main finding of MulTaBench?
Target-aware embeddings — encoders fine-tuned on the prediction target — consistently beat frozen pretrained embeddings across every tabular learner tested, and a small tuned encoder can beat a large frozen one. Tuning the representation to the task matters more than scaling the encoder.
How does MulTaBench decide if a dataset is truly multimodal?
It applies a joint-signal screen (both modalities must beat either alone) and a task-awareness screen (a frozen embedding must not already capture all the useful signal). Of 56 text-tabular candidates, only 41% passed both; about 23% failed joint-signal and 36% of the rest failed task-awareness.
What models does MulTaBench evaluate?
Five primary learners drive curation — LightGBM, CatBoost, TabM, TabPFNv2 and TabPFN-2.5 — with robustness checks adding XGBoost, RandomForest, RealMLP, TabDPT, TabICLv2, TabSTAR, ConTextTab and AutoGluon-Multimodal. Text uses e5 encoders, images use DINO-v3.
What is the biggest weakness of MulTaBench?
Its curation pipeline uses tabular models to select datasets, so the eligibility criterion is entangled with the methods being tested, and those curation models cannot be fairly scored on the benchmark. The target-aware approach also adds real fine-tuning compute over frozen embeddings.
One line: a multimodal tabular benchmark is only useful if the extra modality is actually load-bearing — MulTaBench filters for that, then shows tuning beats scaling. Read the original paper on arXiv.