AI Agents · Agent Memory · Reinforcement Learning
OpenSkill: Self-Evolving LLM Agents With No Task Supervision
OpenSkill lets agents build skills and their own verifiers from the open web, hitting 43.6% on SkillsBench (+8.9 over the best baseline) with zero target-task answers.
Quick answer
OpenSkill is a framework that lets a deployed LLM agent improve at a new task without ever seeing answers, curated skills, or a graded verifier for that task. Instead it pulls knowledge and verification cues from open-world sources (docs, repositories, web pages), distills them into reusable skills, then sharpens those skills against virtual tests it writes for itself.
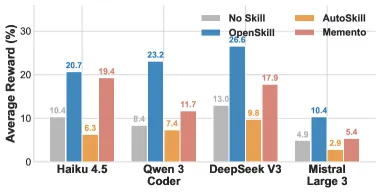
The headline number: on SkillsBench (11 domains), OpenSkill reaches a 43.6% overall pass rate with Claude Code (Opus 4.6), beating the strongest baseline by +8.9 points and landing within a point of the 44.5% human reference. With Codex (GPT 5.2) it hits 42.1% (+8.8). The catch worth knowing up front: this only matters if you genuinely cannot supply task supervision. If you can, simpler skill libraries are cheaper.
The supervision trap OpenSkill is built around
Most “self-evolving agent” work quietly leaks the answer. Skill-library methods assume someone curated good skills; verifier-feedback methods assume a reward signal exists; even retrieval setups often retrieve from the target task’s own materials. The moment an agent hits a genuinely new task after deployment (a fresh API, an internal tool, an unfamiliar domain), those crutches disappear.
OpenSkill takes the hard version of the problem seriously: no target-task supervision of any kind. No answers, no gold tests, no curated skill seeds. The only thing the agent gets is the open world, which is exactly what a human engineer would reach for: documentation, GitHub repos, blog posts, Stack Overflow threads. The contribution is showing you can manufacture both the skill and the grading signal out of that raw material.
How the three-stage pipeline works
Stage 1, Open-World Knowledge Acquisition. The agent retrieves two distinct things: task-relevant knowledge (how to do the thing) and verification anchors (how to tell if the thing was done right). Separating these matters. The second retrieval is what later lets the agent grade itself.
Stage 2, Leakage-Free Skill Evolution. This is the core loop. The agent drafts an initial skill, then builds a virtual test suite from the verification anchors rather than from any real answer. It runs the skill against those virtual tests and uses a diagnostic-driven refinement loop with a gap-versus-bug classifier: did the skill fail because it is missing a capability (a gap) or because of an implementation error (a bug)? That distinction routes the fix. The virtual tests are derived from open-world verification knowledge, never from hidden target answers, which is what keeps the loop leakage-free.
Stage 3, Zero-Shot Target Evaluation. Only here, at evaluation time, does the real ground-truth test appear. The agent never trained against it.
Key results
- SkillsBench, Opus 4.6: 43.6% overall pass rate vs. 34.7% for Skill-Creator, a +8.9 point gain over the strongest baseline, against a 44.5% human reference. OpenSkill closes most of the human gap without supervision.
- SkillsBench, GPT 5.2: 42.1% vs. a 33.3% chain-of-thought baseline (+8.8), human reference 44.8%.
- SocialMaze (6 subtasks): 82.7% with Opus 4.6 (vs. 81.0% Skill-Creator) and 70.7% with GPT 5.2 (vs. 69.8%).
- ScienceWorld: 90.0% with Opus 4.6 (vs. 88.7% SkillNet) and 85.3% with GPT 5.2 (vs. 83.1%).
- Self-built verifier alignment: the virtual verifier reaches 80.5% recall and 56.9% precision against ground-truth outcomes it never accessed, with 88.9% coverage of ground-truth test intent.
Two honest readings of these numbers. First, the big SkillsBench jump (+8.9/+8.8) is the real story: that benchmark is where “build skills from scratch” pays off. On SocialMaze and ScienceWorld the margins are thin (1–2 points), so OpenSkill’s advantage is task-dependent, not universal. Second, the verifier’s 56.9% precision means it flags a lot of false failures; high recall with mediocre precision suggests it errs toward over-rejecting, which is the safer failure mode for a self-grader but does cost iterations.
Why this lands now
Skills are becoming a first-class agent primitive (Claude Code skills, Codex). The open question has been whether an agent can grow its own skills in the field without a human curating them or a benchmark grading them. OpenSkill shows that a self-constructed verifier can stay 80%-aligned with hidden ground truth, and that Opus-generated skills transfer to other models (Figure 3). That is the part that makes the no-supervision claim more than aspirational.
Limits and open questions
- Noisy sources. Web and repo content can be outdated or contradictory; the framework leans on provenance tracking and source validation, which the paper acknowledges but does not fully solve.
- Virtual tests can be too easy. If self-written tests undershoot real difficulty, skill quality is overestimated. And if they accidentally encode hidden answers or verifier behavior, the leakage-free guarantee quietly breaks.
- Cost and latency. Open-world research is more expensive and slower than closed-world skill generation, so the +8.9 gain comes with a compute bill the paper does not fully quantify per task.
- Thin margins outside SkillsBench. On SocialMaze and ScienceWorld the gains are within a couple of points, so don’t expect uniform lift.
FAQ
What makes OpenSkill different from a normal agent skill library?
A skill library assumes someone already curated good skills and, often, a way to grade them. OpenSkill assumes neither. It acquires skills and manufactures its own verification signal from open-world sources, with no target-task answers. That “no supervision” constraint is the entire point.
Does OpenSkill actually beat human performance on SkillsBench?
No, not yet. It reaches 43.6% with Opus 4.6 against a 44.5% human reference: close, but still below. The notable part is getting that near without any task supervision, not surpassing humans.
Should I use OpenSkill if I already have labeled tasks or a verifier?
Probably not. OpenSkill’s value is precisely when you cannot supply supervision. If you have gold answers or a real reward signal, simpler supervised skill methods are cheaper and avoid the extra open-world retrieval cost and latency.