Speech Synthesis · Diffusion Models · Multimodal Models
SwanSphere: Streaming Spatial Audio Generation From Video and Text
SwanSphere streams first-order ambisonic audio synced to video or text, emitting its first chunk in 0.21s while cutting Frechet Distance to 120.28 vs OmniAudio's 157.67. Quality without waiting for the whole clip.
Quick answer
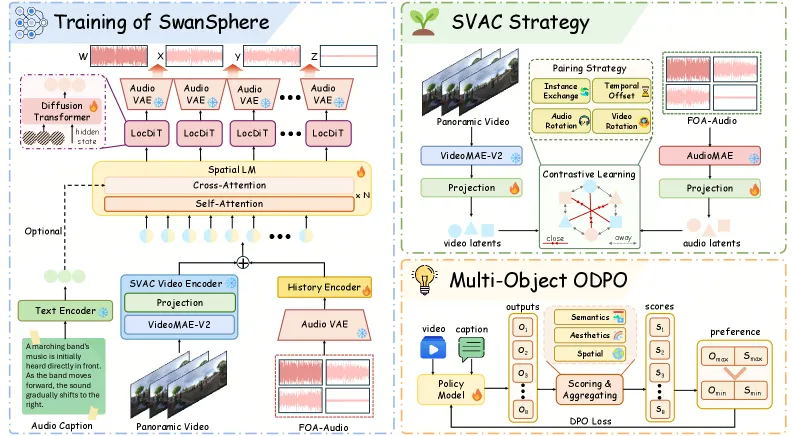
SwanSphere generates spatial audio, meaning four-channel first-order ambisonics (FOA) that encodes where each sound sits in 3D space. It does this in a streaming fashion, so the first chunk leaves the model in 0.21 seconds instead of after the whole clip is rendered. It conditions on either video (matching sound direction to what moves on screen) or text. The design splits work between a Spatial Language Model that predicts semantic tokens autoregressively and a Local Diffusion Transformer (LocDiT) that turns those tokens into continuous FOA waveforms via flow matching. On video-to-spatial-audio it reaches a Frechet Distance of 120.28 against OmniAudio’s 157.67, with directional (angular) error of 1.03 degrees. The model is 1.09B parameters and was accepted at ICML 2026.
Why streaming spatial audio is hard
Spatial audio for video has two jobs at once: sound the right way (timbre, fidelity) and come from the right place (a car passing left-to-right should pan accordingly). Most prior systems treat this as offline batch generation. You feed the full video, wait, and get the whole soundtrack back. That kills any real-time or interactive use (live avatars, AR, game audio) because latency scales with clip length. The naive fix, chunking the audio, breaks spatial coherence: independent chunks drift in direction and timbre across boundaries. SwanSphere’s bet is that an autoregressive backbone with explicit causal conditioning can keep direction consistent across chunks while still emitting audio as it goes.
How SwanSphere works
The pipeline is two-stage. A Spatial Language Model consumes video features (from a VideoMAE encoder) or text and autoregressively predicts a stream of semantic embeddings. This is the causal part that makes streaming possible, because each new chunk is conditioned on what came before. A Local Diffusion Transformer (LocDiT) then decodes those embeddings into high-fidelity continuous spatial audio using flow matching, operating in the latent space of a 4-channel FOA-VAE built specifically for ambisonic signals.
Two training ideas do the heavy lifting. Spatial Video-Audio Contrastive (SVAC) learning aligns the visual motion and the directional content of the audio, so the model learns that an object moving right should produce sound arriving from the right, not just plausible-sounding noise. On top of that, a multi-objective online DPO stage applies preference optimization across several axes at once (fidelity, spatial accuracy, sync) rather than optimizing a single reward. That is a sensible choice given that “good spatial audio” is genuinely multi-criteria.
Inside the data pipeline
Spatial audio datasets barely exist, so much of the contribution is an automated annotation pipeline. The primary SwanSphere set is ~165,000 video-audio pairs (~458 hours) pooled from Sphere360, YT-Ambigen, and newly collected YouTube clips, with 5% held out for test. To bootstrap acoustic quality the authors run curriculum learning over ~1M samples from AudioCaps, VGGSound, WavText5k and AudioSet, converted to a pseudo-FOA format. A separate spatial-caption set of ~3,100 captioned samples (300 reserved for eval) supports the text-to-spatial task. The honest read: the supervised spatial-caption set is small, and the team leans on pseudo-FOA conversion to get scale. That is pragmatic, but it is a likely ceiling on how nuanced the spatial grounding can get.
Key results
- First-chunk latency 0.21s, total generation 9.13s. The streaming claim is the headline, and 0.21s is genuinely interactive-grade.
- Video-to-spatial FD 120.28 vs OmniAudio 157.67, with KL divergence 1.36 vs 1.93 and angular (directional) error 1.03 degrees vs 1.27 degrees. It is better on both quality and localization.
- Text-to-spatial FD 142.80 vs OmniAudio 174.13, KL 1.43 vs 1.83. The same gap holds when conditioning on text instead of video.
- Subjective MOS-SQ 4.32 and MOS-AF 4.44 (video-to-spatial), close to ground-truth ratings of 4.60 and 4.58. Humans rate it near-real for quality and audio-visual fit.
- SELD weighted cosine similarity 0.63 vs OmniAudio 0.41, a sizable margin on the sound-event localization-and-detection probe, the most direct test of “is the sound in the right place.”
- 1.09B parameters, mid-sized rather than a giant model.
Limits and open questions
The authors are candid that spatial captions mostly describe a single dominant source, so multi-source scenes (a concert with several instruments playing from different directions) are not fully modeled, limiting fine-grained spatial disentanglement. That is the real bottleneck: the impressive single-source localization may not survive a busy, polyphonic scene. The reliance on pseudo-FOA conversion for the large curriculum set also means a lot of training signal is synthetic spatial information, not measured. And FD/KL on a 5% in-distribution test split says little about generalization to out-of-domain video. Who should skip it: anyone needing dense multi-source spatial scenes today, or anyone without the FOA playback/rendering stack to actually use ambisonic output.
FAQ
What is SwanSphere and what does it generate?
SwanSphere is a 1.09B-parameter model from Zhejiang University that generates streaming spatial audio, specifically four-channel first-order ambisonic (FOA) audio that carries directional information, conditioned on either an input video or a text description. It was accepted at ICML 2026.
How does SwanSphere achieve low latency in spatial audio generation?
It uses a causal autoregressive diffusion transformer: a Spatial Language Model predicts semantic embeddings chunk-by-chunk so generation can start before the full input is processed, and a Local Diffusion Transformer decodes each chunk via flow matching. This yields a 0.21s first-chunk latency rather than waiting to render the entire clip.
Is SwanSphere better than OmniAudio for video-to-spatial-audio generation?
On the reported benchmarks, yes: SwanSphere reaches FD 120.28 vs OmniAudio’s 157.67, angular error 1.03 vs 1.27 degrees, and SELD weighted cosine similarity 0.63 vs 0.41. The caveat is that complex multi-source scenes remain unmodeled, so the lead is clearest on dominant-single-source content.