Video Generation · Multimodal Models · LLM Reasoning
VLM Teachers Score Video-Model Reasoning at Test Time
Instead of asking a video model to reason directly, a VLM grades its in-progress frames and fine-tunes a per-instance LoRA. The trick lifts RULER-Bench from 46.4 to 68.2.
Quick answer
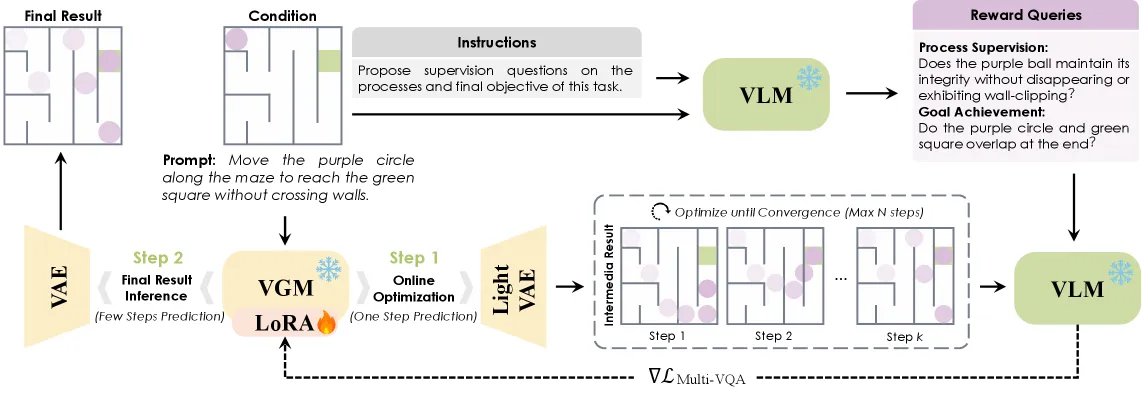
This paper flips the usual setup. Rather than train a video generation model (VGM) to “reason” about a task, it keeps the video model frozen and puts a vision-language model (VLM) in the grader’s seat. For each input, the VLM reads the task, writes its own binary reward questions, watches the video model’s intermediate prediction, and backpropagates a VQA loss into a tiny per-instance LoRA. The video model is the student; the VLM is the teacher who never solves the problem itself but tells the student when it is wrong.
The payoff is concentrated on the harder, more general benchmark: RULER-Bench climbs from a frozen-baseline 46.4 to 68.2, a +21.8-point jump. On the symbolic VBVR-Bench the gain is real but smaller, 0.666 to 0.781 (+0.115). The honest read is that this is a test-time-compute method. It spends optimization steps per instance to buy reasoning the base model could not do in one shot.
How the teacher grades without solving
The teacher never produces an answer video. It does two things. First, given the task condition, it synthesizes one goal-achievement query (did the final frame satisfy the objective?) and M process-supervision queries, with M typically between 1 and 3, that check intermediate steps. Second, during the video model’s denoising it evaluates the predicted frames against those queries as a multi-question VQA problem and turns the answer logits into a differentiable reward.
That reward is what makes the loop work. Because the VLM’s VQA loss is differentiable, gradients flow back through the predicted frames into the LoRA weights of the VGM Reasoner. There is no reinforcement learning, no reward model training, no policy gradient noise. The system is just a frozen video backbone plus a few hundred-thousand adapter parameters nudged toward whatever the teacher’s questions reward. The “adaptive” in the title is a loss-based early-stop: optimization halts once the multi-VQA loss drops below a threshold or hits a step cap N, so easy instances stop early and hard ones get more compute.
Why both reward channels matter
The ablations on VBVR-Bench are the most convincing part of the paper, because they isolate what each piece buys. Dropping the task-specific rewards entirely sends the score from 0.781 to 0.712 (−0.069). Removing the final-goal reward is worse, 0.692 (−0.089); without a clear target the optimization wanders. Removing only the process-supervision queries costs less, 0.758 (−0.023), but still hurts. So the goal query supplies direction and the process queries supply shaping; you want both, and the final goal carries the most weight.
Against the obvious alternatives the method also wins on quality-per-cost rather than just raw score. Pass@5, meaning sampling five videos and keeping the best, reaches only 0.683 on VBVR-Bench and 49.1 on RULER-Bench, far below this method, while VideoTPO actually drops VBVR-Bench to 0.634. Brute-force sampling does not buy reasoning; targeted per-instance optimization does.
Key results
- RULER-Bench: 46.4 → 68.2 (+21.8). This is the headline and the general-purpose test; the large gap suggests the base video model had real latent capability the teacher unlocked.
- VBVR-Bench: 0.666 → 0.781 (+0.115). Symbolic reasoning improves but by less, hinting these tasks are closer to the VLM teacher’s own perception ceiling.
- Beats Pass@5 and VideoTPO. Pass@5 gives only +0.017 / +2.7; VideoTPO is mixed (−0.032 on VBVR-Bench, +3.9 on RULER-Bench). The structured reward beats both.
- Ablations confirm causality. Final-goal reward is the single most important channel (−0.089 if removed); process supervision adds a smaller but real boost.
- R²=0.733 between the teacher VLM’s understanding capability and RULER-Bench score. The method is only as good as the teacher’s eyes.
Limits and open questions
The authors are unusually candid about the failure mode. In a manual audit of 50 failures, only 8 (16%) came from incorrect reward queries; the other 42 (84%) were VLM perception errors. The teacher simply did not see a subtle visual mistake and so rewarded it. That means the ceiling is the teacher, not the optimizer: the R²=0.733 correlation makes this explicit. Swap in a sharper VLM and the numbers should move; nothing here fixes a teacher that misreads the frame.
Two further caveats. The student backbone in the experiments is Wan2.2-5B-Distilled, a step-distilled model, so the paper has to manage decoder artifacts from few-step prediction. It is unclear how the method behaves on a full-step, larger VGM. And per-instance test-time LoRA optimization is not free: this is inference-time training, so latency and compute per query are far above a single forward pass. If you need real-time video reasoning, this is not yet your tool.
FAQ
What does “VLMs are good teachers for video reasoning” actually mean?
The VLM never generates the answer video. It writes binary reward questions about the task, watches the frozen video model’s intermediate frames, and turns its VQA judgments into a differentiable loss that fine-tunes a small per-instance LoRA on the video model. Teacher grades; student (the video model) improves.
How big is the gain over just sampling more videos?
Much bigger. Pass@5, or best-of-five sampling, adds only +0.017 on VBVR-Bench and +2.7 on RULER-Bench, while this method adds +0.115 and +21.8. Extra samples do not create reasoning; the structured reward and per-instance optimization do.
What is the main bottleneck of this approach?
The teacher’s perception. In the paper’s own audit, 84% of failures were the VLM missing a subtle visual error and rewarding a wrong video, and RULER-Bench score correlates with VLM understanding at R²=0.733. A weak or short-sighted teacher caps the whole system.