EvoArena:智能体记忆必须追踪环境变化
EvoArena 把静态智能体任务改造成演化链,当前智能体平均准确率只有 39.6%;EvoMem 用 patch memory 将链级准确率提高 3.7 点。
快速答案
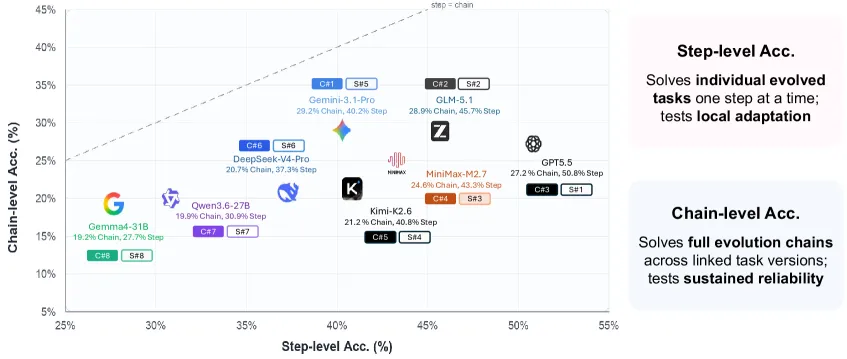
EvoArena 测的是 LLM 智能体能否处理会变化的环境。它把终端任务、软件仓库和长期用户偏好改造成 evolution chain,同时看单步准确率和整条链是否持续成功。论文报告当前 agents 在三个动态领域平均只有 39.6% 准确率。EvoMem 是一个 patch-based memory 附加方法,会记录记忆更新的变化过程;它在 EvoArena 上平均提升 1.5 点,其中 step accuracy 提升 2.6 点,chain-level accuracy 提升 3.7 点。
EvoArena 改变了什么
多数智能体基准默认世界是静止的。工具接口不变,代码仓库状态固定,用户偏好被当成稳定事实。但真实部署里,API 会变、依赖会升级、验证规则会改、用户偏好会在特定条件下被新偏好覆盖。
EvoArena 把这种变化变成可评分任务。它构建有版本顺序的 chain,要求 agent 在每个阶段解决任务,同时保留相关历史。更严格的 chain score 不只看某个孤立版本是否成功,而是看 agent 能否沿着相关版本持续成功。
三个子领域
Terminal-Bench-Evo 会修改终端任务中的 CLI、依赖、输入输出、协议和验证规则。SWE-Chain-Evo 从仓库 milestone 构造软件演化链,前面做过的实现会影响后面任务。PersonaMem-Evo 使用长对话,其中用户偏好会演化、冲突或变成条件化偏好。
规模也足够看出问题。Terminal-Bench-Evo 有 441 个实例,来自 356 条 evolved task chain。SWE-Chain-Evo 有 50 条 evolution chain、493 个 chain-step instance。PersonaMem-Evo 有 505 个问题,对话中位长度约 174.7K token,中位轮数 597。
EvoMem 的机制
EvoMem 不替换原有记忆系统,而是在旁边记录非添加式更新。每个 patch 记录什么变了、为什么变、和之前状态有什么不同、触发变化的证据是什么。检索时,agent 不只拿最新 memory,还可以拿相关 patch。
这正是机制所在。普通 memory update 可能直接覆盖旧规则;patch memory 会保存「从旧规则到新规则的转变」。当后续任务依赖「规则曾经变过」而不是只依赖最新规则时,这个 transition 就有价值。
关键结果
- 当前 agent 难度: base agents 在 Terminal-Bench-Evo step accuracy 为 43.6%,SWE-Chain-Evo 为 29.2%,PersonaMem-Evo 为 46.5%。
- 链级失败: base chain accuracy 更低,Terminal-Bench-Evo 为 21.5%,SWE-Chain-Evo 为 10.6%,PersonaMem-Evo 为 39.1%。
- EvoMem 增益: 摘要报告 EvoArena 平均提升 1.5 点;表格拆分口径下,step accuracy 平均提升 2.6 点,chain accuracy 提升 3.7 点。
- 标准基准: 摘要报告 GAIA 提升 6.1 点、LoCoMo 提升 4.8 点;Table 4 的展示口径是 GAIA +6.5、LoCoMo +3.3。
- 机制证据: PersonaMem-Evo 的 evidence capture 从 89.4% 到 90.3%,提升很小,但方向符合 patch memory 的解释。
局限与存疑
EvoArena 比静态 benchmark 强,但环境变化仍然被整理得比较干净。真实生产环境里的变化通常文档不完整、用户表达含糊、组织记忆混乱。EvoArena 为了可评分,把这些变化包装成更清晰的版本链。
EvoMem 的提升也不能夸大。3.7 点 chain accuracy 提升有意义,但远不能让智能体可靠。更准确的结论是:记录记忆变化历史比只保留最新状态更合理,但 agent memory 还没有解决。
还缺少的证据很实际。论文没有证明它能处理生产环境里的混乱文档、部分失败、权限变化和含糊用户反馈。patch 检索会带来多少 token 成本、模型什么时候会忽略 patch、加了 patch 后长链失败主要来自哪里,这些也还需要拆解。
对构建者来说,结论要分场景。做长期运行的 coding agent、运维 agent 或个人记忆 agent,可以优先试 patch history。只做短会话 QA 或静态检索助手,没有必要先迁移到这种记忆结构。
常见问题
为什么 EvoArena 的 chain accuracy 低于 step accuracy?
chain accuracy 要求 agent 沿着相关版本持续成功。模型可能解出某个孤立快照,但在 CLI、依赖、仓库状态或用户偏好变化后失败,所以链级分数会暴露单步分数掩盖的脆弱性。
EvoMem 在 EvoArena 中是什么?
EvoMem 是 patch-based memory 方法。它把重要记忆更新记录为结构化 patch,并在后续任务中把 patch 和最新 memory 一起检索出来。
EvoMem 相比 latest-state memory 多改进了什么?
latest-state memory 可能覆盖旧规则,也会丢掉为什么改变。EvoMem 保留 transition patch,让 agent 在后续任务中看到旧状态、新状态和触发更新的证据。
EvoArena 对当前智能体有多难?
论文报告当前 agents 在动态环境中平均准确率为 39.6%。链级分数更低,例如 Terminal-Bench-Evo base chain accuracy 为 21.5%,SWE-Chain-Evo 为 10.6%。
EvoMem 是否解决了智能体记忆?
没有。EvoMem 平均把 chain-level accuracy 提高 3.7 点,但剩余失败率仍然很高。它证明的是记忆系统应该保留更新历史,而不是只保存最新状态。
一句话:EvoArena 的价值在于它测 agent 是否记得世界如何变化,而不只是记住世界当前是什么样子。阅读 arXiv 原文。