看、记、想:视频多模态大模型的人类视角综述
综述把长视频 MLLM 重构为「看-记-想」三种能力,对比 11 篇已有综述,梳理 100+ 方法与 5 个应用领域。
快速答案
这是一篇综述,不是新模型。它的核心判断是:视频 MLLM 文献已经碎成几十个互不相关的基准,补救办法是别再按数据集去索引论文,而是按模型真正要做的事去组织:看(从视频流里取证据)、记(在几分钟到几小时里保住上下文)、想(给出有依据的答案)。作者把一个视频系统形式化为四个部件:感知表示、记忆状态、推理轨迹、最终预测,整个领域都挂在这副骨架上。
如果你在做长视频或流式视频系统,又受够了那种只按年份罗列模型的综述表格,这篇确实有用:它告诉你某个方法到底攻的是哪个子问题。如果你想要新的实验结果或新架构,可以跳过:这里没有新模型,也没有新基准。
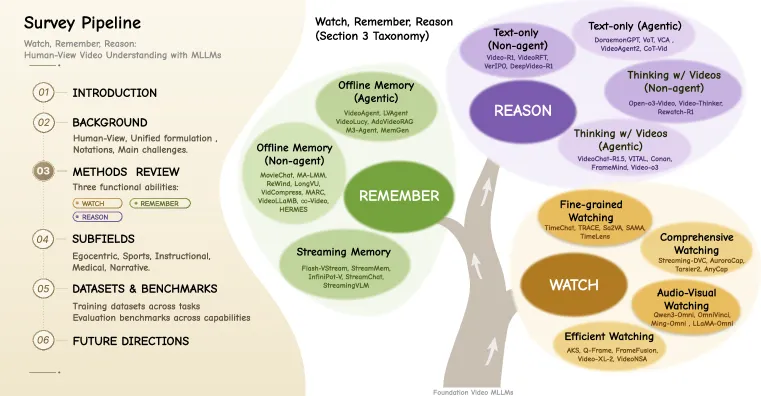
「看-记-想」三段拆解
真正的贡献是这套分类法,而且比多数综述更干净。每个支柱都拆成具体子线:
- 看有四个维度:细粒度时空定位(在哪、在何时)、综合描述(整段、密集、区域级)、用于全模态感知的音视频融合,以及靠帧选择和 token 压缩做的效率优化。TimeChat、LITA、UniTime、Sa2VA 等落在这里。
- 记分为离线记忆(有 / 无 agent,采用分层或事件图结构,如 MovieChat、VideoAgent、LongVU)和流式记忆(KV-cache 优化、双记忆架构)。这是标题里「记」这个动词真正立得住的地方:综述把记忆当作一等的系统状态,没把它当成事后补丁。
- 想把纯文本推理(agent 式工具调用 vs. 非 agent 式后训练,如 Video-R1、VITAL)与「用视频思考」分开,后者让模型把推理步骤和视觉定位交织起来(Open-o3-Video、Pixel Reasoner)。
这套框架的长处在于,它对应了一条真实的瓶颈流水线:证据稀疏且散落在长视频流里(看)、上下文撑爆窗口(记)、答案逐渐偏离真正看到的内容(想)。它的短处是这三种能力并不能干净切分:「用视频思考」本身就是推理回头驱动观看。综述没有假装这些盒子彼此不漏,而是直接承认了这种重叠。
关键结果
用数字说话:综述在对比表里把自己摆在 11 篇已有综述之列,组织了 100+ 个代表性方法,并补上 5 个应用子领域:第一人称(egocentric)、体育、教学、医疗、叙事视频。光是「看」这一支柱就拆成 4 个互补维度。它串起的数据集包括 ActivityNet Captions、MSVD、MSR-VTT、ShareGPT4Video、Panda-70M、LLaVA-Video-178K;基准则覆盖视频描述完整度(VDC)、视频时序定位(VTG)、密集描述与视频问答。
应用领域那一节,多数读者会略读,但其实不该略。第一人称和流式视频恰恰是「看-记-想」张力最尖锐的地方:你没法倒带一个实时的第一人称画面,所以感知、记忆、推理都得在线进行,而且预算固定。综述把流式第一人称理解标为开放前沿,这个判断是诚实的。
为什么这套重构现在重要
视频理解已经从短片转向长的、多模态的、知识密集的素材,而这个转向打破了短片基准赖以成立的假设。30 秒的片段能让你把每一帧都硬塞进上下文窗口;一小时的视频不行。一旦接受这个约束,领域的开放问题就不再是「在数据集 X 上刷更高的准确率」,而是稀疏证据检索、固定算力预算下的长程依赖,以及对真正看到内容保持忠实的推理。综述的价值,就在于把这次重构讲明白,并给每个开放问题在分类法里安一个有名字的位置。
局限与存疑
最明显的局限是:在这种节奏的领域里,综述老化得很快。这份 100+ 方法的快照是 2026 年的一张照片,而像 Open-o3-Video 这类「用视频思考」的方法还非常早期,推理分支的分类一年内可能就得重接线。它也没有定量的元分析:论文只组织方法,不跑头对头数字,所以它告诉你「有什么」,不告诉你「哪个更好」。想要「任务 Y 用方法 X」结论的读者,还是得去读原始论文。
未来方向那一节倒是把真正的缺口点得很诚实:视频里的空间推理(而不只是时序)、多视频与多片段定位、带结构化记忆的小时级理解、高效且可验证的推理,以及流式第一人称理解。这些都还没解决,综述也没装作解决了。
常见问题
这篇视频 MLLM 综述里的「看-记-想」框架是什么?
它是对视频理解的一种人类视角拆解,分为三种能力:看(从多模态流里取任务相关证据)、记(在长视频或流式视频里保住关键上下文)、想(给出有依据的答案)。综述把任意视频系统形式化为感知表示、记忆状态、推理轨迹、最终预测,再把 100+ 方法挂到这三个支柱下。
Watch, Remember, Reason 这篇论文提出新模型或新基准了吗?
没有。它是综述和分类法论文,对比了 11 篇已有综述,它组织的是 TimeChat、Sa2VA、MovieChat、LongVU、Video-R1、Pixel Reasoner 等现有工作,本身没有提出新架构或发布新基准。请把它当成领域地图用,它不是新实验结果的来源。
哪些人该读这篇人类视角视频理解综述?
做长视频、流式或第一人称 MLLM 系统的工程师和研究者:它能让你看清某个方法攻的是哪个子问题。关于流式第一人称视频和结构化小时级记忆的应用章节最有可操作性。期待新准确率数字或新模型的人,应该看别处。