Multimodal Models · Agent Memory · LLM Reasoning
Watch, Remember, Reason: A Human-View Map of Video MLLMs
A survey that reframes long-video MLLMs as three abilities (watch, remember, reason), comparing against 11 prior surveys and organizing 100+ methods plus 5 application domains.
Quick answer
This is a survey, not a new model. Its bet is that the video-MLLM literature has fragmented into dozens of disconnected benchmarks, and the fix is to stop indexing papers by dataset and start indexing them by what the model actually has to do: watch (acquire evidence from the stream), remember (hold context across minutes or hours), and reason (produce a grounded answer). The authors formalize a video system as four components (perceptual representation, memory state, reasoning trace, and final prediction) and hang the whole field off that skeleton.
If you are building a long-video or streaming-video system and you are tired of survey tables that just list models by year, this one is genuinely useful: it tells you which sub-problem a method attacks. If you want fresh empirical results or a new architecture, skip it. There is no new model and no new benchmark here.
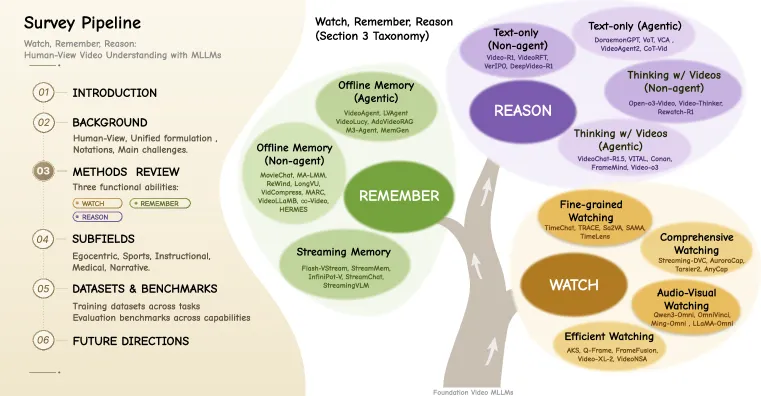
The watch–remember–reason decomposition
The core contribution is the taxonomy, and it is cleaner than most. Each pillar splits into concrete sub-tracks:
- Watch has four dimensions: fine-grained spatio-temporal grounding (where and when), comprehensive captioning (whole-video, dense, and region-level), audio-visual integration for omni-modal perception, and efficiency via frame selection and token compression. Methods like TimeChat, LITA, UniTime, and Sa2VA land here.
- Remember splits into offline memory (agentic and non-agentic, with hierarchical or event-graph structures such as MovieChat, VideoAgent, LongVU) and streaming memory (KV-cache optimization, dual-memory architectures). This is the part the title’s “remember” verb actually earns: the survey treats memory as a first-class system state, not an afterthought.
- Reason separates text-only reasoning (agentic tool-use vs. non-agentic post-training, e.g. Video-R1, VITAL) from “thinking with videos,” where the model interleaves reasoning steps with visual grounding (Open-o3-Video, Pixel Reasoner).
The framing’s strength is that it maps to a real bottleneck pipeline. Evidence is sparse and scattered across a long stream (watch), context overflows the window (remember), and answers drift from what was actually seen (reason). The framing’s weakness is that the three abilities are not cleanly separable: “thinking with videos” is reasoning that loops back into watching. The survey acknowledges this overlap rather than pretending the boxes are airtight.
Key results
By the numbers: the survey positions itself against 11 existing surveys in a comparison table, organizes 100+ representative methods, and adds 5 application subfields: egocentric, sports, instructional, medical, and narrative video. The “watch” pillar alone is split into 4 complementary dimensions. Datasets it threads through include ActivityNet Captions, MSVD, MSR-VTT, ShareGPT4Video, Panda-70M, and LLaVA-Video-178K; benchmarks span video description completeness (VDC), video temporal grounding (VTG), dense captioning, and video QA.
The application-domain section is the part most readers will skim but probably shouldn’t. Egocentric and streaming video are where the watch/remember/reason tension is sharpest. You cannot rewind a live first-person feed, so perception, memory, and reasoning all run online and under a fixed budget. The survey flags streaming egocentric understanding as an open frontier, which is the honest call.
Why this framing matters now
Video understanding has shifted from short clips to long, multimodal, knowledge-intensive footage, and that shift breaks the assumptions short-clip benchmarks were built on. A 30-second clip lets you brute-force every frame into the context window; an hour of video does not. Once you accept that constraint, the field’s open problems are no longer “higher accuracy on dataset X.” They are sparse-evidence retrieval, long-range dependency under a fixed compute budget, and reasoning that stays faithful to what was actually perceived. The survey’s value is making that reframing explicit and giving each open problem a named home in the taxonomy.
Limits and open questions
The obvious limit is that a survey ages fast in a field moving this quickly. The 100+ methods snapshot is a 2026 photograph, and “thinking with videos” methods like Open-o3-Video are early enough that the taxonomy’s reasoning branch may need rewiring within a year. There is also no quantitative meta-analysis: the paper organizes methods but does not run head-to-head numbers, so it tells you what exists, not which is best. Readers wanting “use method X for task Y” will still have to read the primaries.
The future-directions section names the real gaps honestly: spatial reasoning in video (not just temporal), multi-video and multi-segment grounding, hour-scale understanding with structured memory, efficient and verifiable reasoning, and streaming egocentric understanding. None of these are solved, and the survey does not pretend otherwise.
FAQ
What is the “watch, remember, reason” framework in this video MLLM survey?
It is a human-view decomposition of video understanding into three abilities: watching (acquiring task-relevant evidence from the multimodal stream), remembering (preserving salient context across long or streaming video), and reasoning (producing grounded answers). The survey formalizes any video system as perceptual representation, memory state, reasoning trace, and final prediction, then organizes 100+ methods under these pillars.
Does the Watch, Remember, Reason paper propose a new model or benchmark?
No. It is a survey and taxonomy paper. It compares itself against 11 prior surveys and organizes existing work such as TimeChat, Sa2VA, MovieChat, LongVU, Video-R1, and Pixel Reasoner, rather than introducing a new architecture or releasing a benchmark. Use it as a map of the field, not a source of new empirical results.
Who should read this human-view video understanding survey?
Engineers and researchers building long-video, streaming, or egocentric MLLM systems who want to see which sub-problem a given method targets. The application sections on streaming egocentric video and structured hour-scale memory are the most actionable. Anyone expecting fresh accuracy numbers or a new model should look elsewhere.