Flow-OPD:用在线蒸馏化解文生图 RL 的奖励冲突
Flow-OPD 给每个奖励单独训一个专家教师,再在线蒸馏进同一个 SD3.5 学生,把 GenEval 从 0.63 拉到 0.92、OCR 从 0.59 拉到 0.94,且不损画质。
快速答案
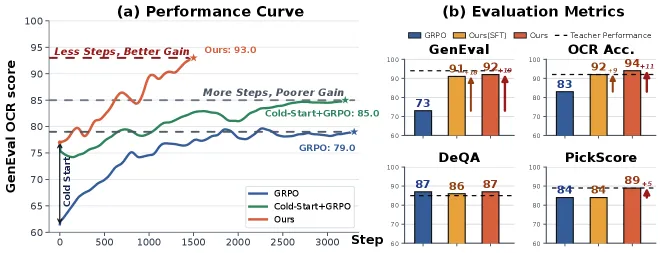
Flow-OPD 在 Stable Diffusion 3.5 Medium 上把 GenEval 从 0.63 提到 0.92、OCR 准确率从 0.59 提到 0.94,同时画质与人类偏好分不降反升。关键在于:它拒绝让一个模型同时优化多个奖励,而是给每个奖励(指令对齐、文字渲染、美学)单独训一个 GRPO 专家教师,再把它们在线蒸馏进同一个学生。在论文的 GenEval+OCR 合并奖励曲线上,学生爬到约 93,而原版 GRPO 早早停在 79 附近。
它真正解决的奖励冲突问题
摘要没点透的实话:这是一篇讲奖励互相打架的论文,而不是讲新采样器。当你把多个奖励加在一起、对流匹配文生图模型跑 GRPO 时,奖励会内斗——使劲优化 OCR(图里文字清不清楚)会拖垮指令对齐,使劲优化美学又让模型钻空子,生成过饱和、千篇一律的图。原版多奖励 GRPO 会过早收敛到一个平庸的折中,论文显示它在合并奖励上卡在 79 左右,而本方法能到约 93。
Flow-OPD 的判断是:不该逼一个策略同时优化互相矛盾的目标。先拆解,后重组。
两阶段方法怎么跑
第一阶段是专家教师。每个奖励各自对基座流模型做一次 GRPO 微调,这样某个教师可以放开手脚冲 OCR,而不必担心毁掉美学。这一步便宜且成熟——单奖励 GRPO 之所以稳,正因为没有冲突。
第二阶段是多教师在线蒸馏,这才是真正的贡献。学生生成自己的去噪轨迹(on-policy),在每个时间步,对应的教师在预测的向量场上给出稠密监督信号,而不是只在终点给一个稀疏的最终图像奖励。由于流匹配是沿 ODE 路径预测速度场,教师与学生可以在学生实际走过的轨迹上逐步对比。这种稠密的在线信号,比只在生成末尾才到的标量 RL 奖励样本效率高得多。
流形锚定正则为何关键
流形锚定正则(Manifold Anchor Regularization, MAR)是阻止学生偏离自然图像流形的那一环。作者冻结一个专门为画质调好的教师,用时间加权的 L2 距离惩罚学生向量场对该冻结教师的偏离。效果是:学生能从其他教师那里吸收对齐和 OCR 能力,同时一个锚点把它的轨迹拉在高保真图像空间附近。这正是它对 RL 经典毛病的回应——奖励黑客式地刷高指标,却悄悄把图越生越难看。
关键结果
- GenEval:0.63 → 0.92(合并后的 Flow-OPD 学生,基座为 SD-3.5 Medium)。
- OCR 准确率:0.59 → 0.94,涨幅最大,反映了专职文字渲染教师的作用。
- DeQA 4.35、PickScore 23.08(合并学生),对比 SD-3.5-M 基线的 4.07 与 21.64——画质和人类偏好上升而非下降,这正是 MAR 的意义所在。
- 合并奖励训练曲线: Flow-OPD 爬到约 93,原版 GRPO 早早收敛在 79 附近。
- 泛化(T2I-CompBench): 在组合性维度上报告了 SOTA——颜色 0.8298、形状 0.6292、三维空间 0.4565、数量 0.6837。
局限与存疑
成本是被转移而非消失了。现在要训 N 个专家教师外加一个蒸馏阶段,总算力比单跑一次 GRPO 更高,即便每个教师本身很稳。论文只在一个基座(SD-3.5 Medium)上验证,在更大流模型或视频流匹配上能否成立,这里没测。奖励集合也是人工挑的——GenEval、OCR、美学——每加一个新目标就得再训再蒸一个教师,扩到几十个奖励并不显然可行。最后,OCR 涨幅之所以这么大,部分是因为 SD-3.5-M 基线本就不擅长文字,读者不应把 0.94 当成普适的文字渲染结论。
常见问题
Flow-OPD 和 GRPO 有什么不同?
Flow-OPD 不在一个策略里同时优化多个相互冲突的奖励。它给每个奖励单独训一个 GRPO 专家,再以逐时间步的稠密监督把它们在线蒸馏进同一个学生;而 GRPO 把所有奖励一次性加上去,得到的是更差的折中。
Flow-OPD 把文生图质量提升了多少?
在 Stable Diffusion 3.5 Medium 上,它把 GenEval 从 0.63 提到 0.92、OCR 准确率从 0.59 提到 0.94,同时 DeQA 与 PickScore 也上升,说明美学被保住而非被牺牲。
Flow-OPD 里的流形锚定正则是什么?
它是一个时间加权的 L2 惩罚,让学生向量场贴近一个冻结的、为画质调好的教师,把生成轨迹锚在自然图像流形上,使强化信号无法以牺牲视觉保真度的方式钻空子。
Flow-OPD 只能用于流匹配模型吗?
该方法围绕流匹配的速度场轨迹设计,这正是稠密在线蒸馏得以成立的前提;论文在一个流匹配扩散模型(SD-3.5 Medium)上做了验证,并未声称覆盖其他生成器家族。
一句话:把互相冲突的奖励拆成专家教师,再沿流轨迹在线蒸馏,并给学生加锚点防止作弊。阅读 arXiv 原文。