Stream-R1:可靠性与困惑度感知的视频蒸馏
Stream-R1 用视频奖励分数和逐区域困惑度给 DMD 损失重新加权,1.3B 流式模型在 VBench 拿到 84.40,反超 14B 教师的 84.26,且仍是 23.1 FPS。
快速答案
Stream-R1 让流式视频蒸馏开始关注监督信号「落在哪里」。它不再对每一帧 rollout、每一个像素都用相同权重去优化,而是按两个信号给损失重新加权:每条生成 rollout 有多可靠(用预训练视频奖励模型打分),以及每个时空区域有多不确定(困惑度)。在 VBench 上,这个 1.3B 学生模型总分达到 84.40,超过它的 14B 教师 Wan2.1 的 84.26 和 Reward Forcing 基线的 84.13——而且仍是 23.1 FPS,不改架构、不增加任何推理开销。
问题:浪费信号的蒸馏
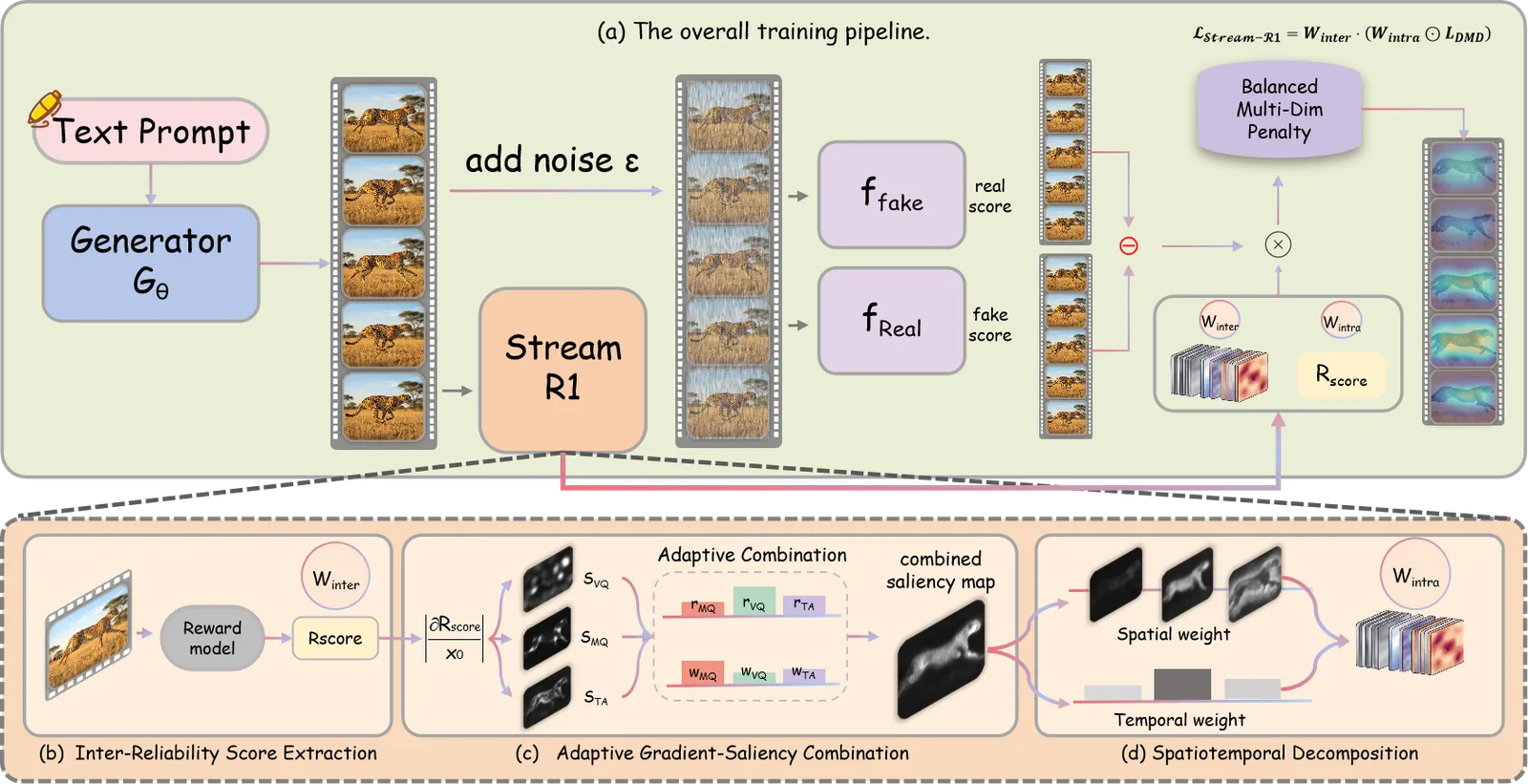
自回归流式视频扩散是一块一块(chunk by chunk)地生成视频,这样才能实时边算边看。为了够快,要把多步的重型教师蒸馏成几步的学生,常用的是分布匹配蒸馏(DMD)。作者盯住的痛点是:标准 DMD 把所有监督都当成信息量相等。每条采样 rollout 在损失里权重一样,每一帧里每个区域也被同样对待——可现实是,有些 rollout 几乎是废品,而有些区域(剧烈运动、精细纹理)正是学生失手的地方,平坦背景却早就学好了。
这种一视同仁就是漏点。梯度预算被花在没什么可教的 rollout 和区域上,真正难的样本反而被稀释。Stream-R1 的判断是:不必加数据、不必扩模型、不必拖慢推理,只要给已有目标重新加权,质量就能白捡回来。
两级加权怎么工作
这套框架叫「可靠性-困惑度感知奖励蒸馏」,把思路拆成两个轴。
Inter-Reliability(rollout 之间)。 每条生成的 rollout 由预训练视频奖励模型打分,这个分数用来重新缩放该 rollout 在蒸馏损失里的贡献。奖励模型信任的高质量 rollout 权重更大;不可靠的被压低,免得把学生往坏模式上拽。这是「该信哪条样本」的轴。
Intra-Perplexity(rollout 内部)。 在每条 rollout 内部,损失被集中到那些「精修收益最大」的时空区域,用困惑度来度量。高不确定的区域——通常是运动复杂或细节密集处——拿到更大的优化压力;学生已经能自信预测的区域则减少。这是「该盯帧里哪一块」的轴。
两者合起来,学生从可信的 rollout 上学得更狠,把力气集中在自己最弱的区域。关键在于:这两个信号只在训练时作用于损失权重,所以部署出来的模型在体积和速度上与普通 DMD 学生完全一致。
关键结果
以下数字来自论文评测;学生是 Wan2.1-T2V-1.3B,从 Wan2.1-T2V-14B 教师在 832×480 下蒸馏而来。
- VBench(5 秒短视频): Stream-R1 总分 84.40(质量 85.14,语义 81.44),高于 14B 教师 Wan2.1 的 84.26 和 Reward Forcing 基线的 84.13。一个 1.3B 的几步学生在综合分上反超自己的 14B 多步教师,是最抢眼的一点。
- 推理速度: 832×480 下 23.1 FPS,去噪步为
[1000, 750, 500, 250]、每块 3 个潜帧——真正的实时流式,且不被方法拖慢。 - 60 秒长视频(Qwen3-VL 评判): 视觉质量 4.92、运动动态 4.04、文本对齐 4.11——生成远超短片训练时长后,增益依然成立。
- 人类偏好(50 个视频、60 秒): 动态合理性胜率 63.0%、视觉质量 60.0%、总体偏好 57.0%,均对比基线。
- 训练成本: 8 张 A100、1000 个优化步、有效批量 64,约 56 小时——对视频模型而言不算贵。
诚实地说:VBench 上对教师的领先很薄(84.40 对 84.26),所以更有说服力的是长视频和人类偏好的差距——在 60 秒的 rollout 上,重新加权的效果会比 5 秒时累积得更明显。
为什么现在重要
流式、实时视频生成是这个领域正在猛推的方向——交互世界、实时数字人、类游戏 rollout——瓶颈在于要便宜到能跑几步。Stream-R1 的贡献是它改的是训练目标而非架构,所以增益在推理时是免费的。这让它像一个即插即用的点子:任何基于 DMD 的流式管线,原则上都能加上可靠性与困惑度加权,而不必动部署模型。
局限与存疑
这套做法继承了奖励模型的盲区。Inter-Reliability 的上限取决于它所信任的那个预训练视频奖励分数;若奖励模型有偏或可被钻空子,重新加权会把偏差放大。VBench 对教师的提升小到接近噪声,所以论证主要压在 60 秒人类偏好结果上,而那只来自 50 个视频。所有结论都只在单一骨干(Wan2.1,1.3B 学生 / 14B 教师)、单一分辨率上给出——还没有证据表明两级加权能迁移到别的蒸馏配方或更大的学生。此外,基于困惑度的区域加权会增加训练期的记账;论文报告推理不变慢,但相对普通 DMD 的训练开销并非重点。
常见问题
Stream-R1 是什么?
Stream-R1 是面向流式(自回归、逐块)视频扩散的奖励蒸馏框架。它用两个信号给分布匹配蒸馏(DMD)损失重新加权——来自视频奖励模型的逐 rollout 可靠性,以及逐区域困惑度——让几步学生在可信样本和自己的弱区域上训练得更狠。
Stream-R1 凭什么超过教师?
在 VBench 上,1.3B 的 Stream-R1 学生总分 84.40,而 14B 的 Wan2.1 教师为 84.26。重新加权让几步学生把优化集中在最关键处;短片上领先很窄,但在 60 秒视频和人类偏好上拉大(总体胜率 57.0%)。
Stream-R1 会拖慢推理吗?
不会。可靠性和困惑度两个信号都只在训练时改变损失权重。部署出来的学生在体积(1.3B)和速度(832×480 下 23.1 FPS)上与标准 DMD 学生完全相同——不改架构,也不增加推理开销。
Stream-R1 用了哪些模型和基准?
学生是 Wan2.1-T2V-1.3B,从 Wan2.1-T2V-14B 在 832×480 下蒸馏,8 张 A100 训练 1000 步。评测用 VBench 评 5 秒短片、用 Qwen3-VL 评判 60 秒视频,外加一个 50 个视频的人类偏好实验。
一句话:别去多生成——把你已有的损失,按「该信哪条样本、哪块区域更难」重新加权。阅读 arXiv 原文。