从上下文到技能:Ctx2Skill 让大模型自进化学技能
Ctx2Skill 用多智能体自博弈,无需人工标注或外部奖励,从长上下文中挖出自然语言技能,把 GPT-4.1 从 11.1% 提到 16.5%。
快速答案
Ctx2Skill 能把一段又长又专业的上下文,自动转化成可复用的自然语言技能——全程不需要人工书写技能标注,也没有外部奖励信号。一个「挑战者-推理者-裁判」自博弈循环负责生成探测任务、在不断进化的技能集下尝试求解、再用二元反馈打分。把挖出的技能塞回模型,CL-bench 上的解题率随之上升:GPT-4.1 从 11.1% 升到 16.5%,GPT-5.1 从 21.2% 升到 25.8%。但要诚实地说:提升真实且在众多模型上一致,可绝对分数很低——即便最强的辅助模型也只解出约四分之一的上下文学习任务。
问题:上下文超出了参数知识
很多真实任务会丢给模型一份信息密集的文档——一本规则手册、一份实验流程、一册领域说明——要求它在权重里根本没有的知识上做推理。直觉解法是「推理时技能增强」:把上下文里的规则与流程抽成模型可以照着执行的显式技能。但有两道坎。其一,为又长又专业的上下文手写技能成本高得离谱。其二更有意思:没有任何自动信号能告诉你某条技能到底有没有用——不像数学和代码,上下文学习没有可对照的验证器。Ctx2Skill 整套设计,就是在回答这个缺失的反馈信号。
自博弈循环如何自造反馈
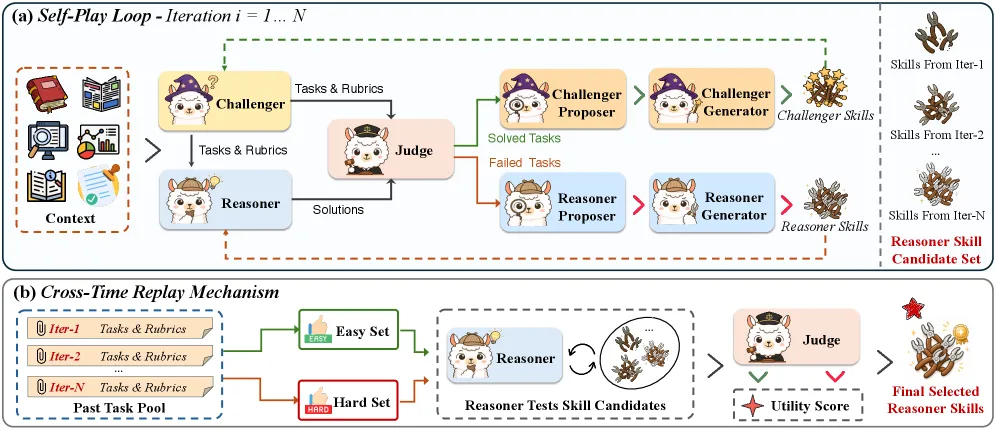
三个智能体围绕每段上下文跑一个循环。挑战者从上下文里生成探测任务和评分细则;推理者在逐轮成长的技能集引导下尝试求解;中立的裁判回传二元的通过/失败反馈。巧妙之处在于挑战者和推理者都会进化:专门的提议者和生成者智能体读取失败案例,把它们综合成针对两端的定向技能更新。于是系统自己引导出训练信号——失败变成新技能,挑战者学着出更难的题,推理者学着应对。循环跑 N=5 轮、每轮 M=5 个任务,也就是约 25 个挑战者任务推动一段上下文的进化。
为什么需要跨时回放
纯粹的对抗式自博弈会崩坏。挑战者会越漂越极端,推理者则在只适配后期病态案例的技能上过拟合——这就是「对抗坍缩」。Ctx2Skill 用跨时回放机制对冲:它不盲信最终技能集,而是回看所有轮次,挑出在代表性案例上取得最佳平衡的那一套技能。实测中,早期轮次被选中的频率最高,只有知识结构复杂的上下文才更多选用后期轮次。正是这一步让挖出的技能可泛化、而非过拟合到自博弈的尾巴上,也是全文方法层面最站得住脚的贡献。
关键结果
- GPT-4.1: 用上 Ctx2Skill 技能后,CL-bench 解题率从 11.1% 升到 16.5%。
- GPT-5.1: 从 21.2% 升到 25.8%,是论文报告中最强的辅助结果。
- 多模型一致: 论文在 GPT-5.2、Claude Opus 4.5、Gemini 3 Pro、Kimi K2.5、DeepSeek V3.2 等更多模型上都观察到同方向的提升。
- 分类增益(GPT-4.1): 流程任务执行提升约 +7.2%、领域知识推理约 +6.2%,而规则系统应用涨幅较小,约 +2.8%。
- 技能质量: 技能质量评分中 Ctx2Skill 得 89.8/100,高于 AutoSkill4Doc 基线的 86.2 与朴素提示基线的 81.8。
- CL-bench 规模: 500 段上下文、1,899 个任务、31,607 条评分细则,平均每段上下文 10.4K token、最长达 65.0K token。
局限与存疑
绝对解题率是房间里的大象:一个最强辅助模型也只得 25.8% 的基准,难度极大,而 +4 到 +5 个百分点的提升虽一致,却仍把多数任务留在了未解状态。增益也并不均匀——规则系统应用几乎没动(约 +2.8%),说明技能这种形式更利于流程、而非死板的规则遵循。自博弈并不便宜:每段上下文五轮、共 25 个任务,每个任务又牵涉多次智能体调用,平摊到单篇文档上是不小的推理开销。而且裁判只给二元反馈、没有真值验证器,质量上限取决于裁判判得对不对——自生成的信号可能强化自己的盲区。挖出的技能能否跨上下文迁移、还是必须逐篇重挖,是决定它实用与否的开放问题。
常见问题
Ctx2Skill 是什么?
Ctx2Skill 是一个自进化框架,能在无人工监督、无外部奖励的前提下,自动从给定上下文中发现、精炼并筛选自然语言技能。这些技能可以塞进任意语言模型,提升其上下文学习能力。
Ctx2Skill 没有外部反馈是怎么工作的?
Ctx2Skill 用多智能体自博弈循环自造反馈:挑战者出探测任务,推理者带着进化中的技能集求解,裁判给二元的通过/失败信号。提议者与生成者智能体把失败转化为新技能,于是系统不靠验证器或人工标注也能改进。
Ctx2Skill 能把大模型性能提升多少?
在 CL-bench 上,它把 GPT-4.1 的解题率从 11.1% 提到 16.5%、GPT-5.1 从 21.2% 提到 25.8%,并在 GPT-5.2、Claude Opus 4.5、Gemini 3 Pro 等其他模型上取得同方向的一致提升。
Ctx2Skill 里的跨时回放是什么?
跨时回放通过在所有自博弈轮次中挑出对代表性案例最平衡的技能集,来防止对抗坍缩——而不是盲目保留最终那套过拟合的技能。早期轮次被选中的频率最高。
一句话:Ctx2Skill 为上下文学习补上了它通常缺失的反馈信号,但仍然偏低的绝对分数,说明上下文推理还有很长的路要走。阅读 arXiv 原文。