Lens:用约 19% 算力训出的 38 亿参数文生图模型
微软 Lens 是 38 亿参数的文生图扩散模型,靠给每张图配上百词长描述,仅用 Z-Image 约 19.3% 的训练算力就追平 60 亿+ 参数对手。
快速答案
Lens 是微软推出的 38 亿参数文生图扩散 Transformer,在质量上追平 60 亿+ 参数模型,却只用了 Z-Image 约 19.3% 的训练算力——约 192K 张 A100 GPU 小时,对比 Z-Image 的 314K 张 H800 GPU 小时。真正的杠杆不是新架构,而是数据密度:Lens 在 Lens-800M 上训练,这 8 亿组图文对的描述由 GPT-4.1 生成,平均每条约 109 个词。它在 GenEval 上得 0.525、在 OneIG(英文)上得 0.557,单张 H100 生成一张 1024 见方图像耗时 3.15 秒,4 步的 Turbo 版仅需 0.84 秒。
为什么「长描述」才是核心
Lens 真正有意思的论点是:训练文生图模型的主要成本,不在扩散骨干,而在每张图携带多少信息。标签式的短描述,逼模型看过几百万张图才学会一个概念。Lens 改为给每张图配一条约 109 词的 GPT-4.1 描述,讲清布局、属性、文字内容与风格,于是单个训练样本在每一步梯度里教给模型的东西多得多。团队认为这正是 38 亿模型能在没有对应算力预算的情况下收敛到 60 亿级质量的原因——你把 GPT-4.1 的标注成本一次性付清,而不是无止境地烧 GPU 小时。
这个说法值得推敲,因为「数据更密胜过参数更多」并非首次被提出,且很难干净地归因。好在 Lens 用了描述长度的消融实验(图 4)来支撑,而非空口断言。
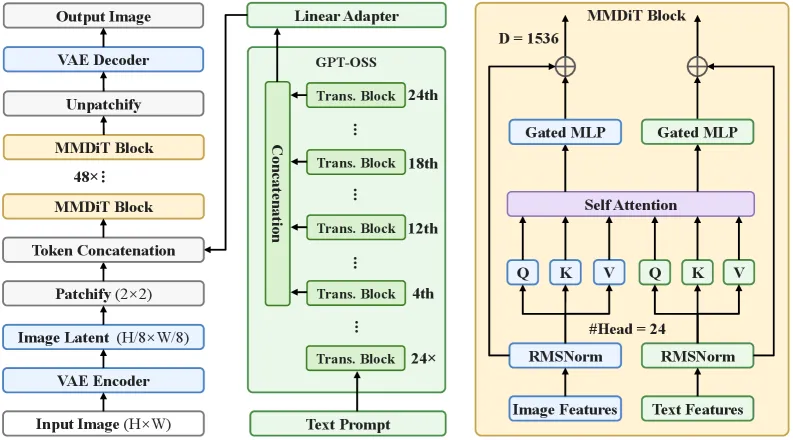
Lens 是怎么搭起来的
Lens 是 MMDiT 家族的潜空间扩散 Transformer:48 个 MMDiT 块,采用 RMSNorm 与 RoPE。两个组件选择很关键。其一,它用语义 VAE——FLUX.2 VAE——作为分词器,这是通过 VAE 消融选出的,理由是带语义结构的潜空间比纯重建式的收敛更快。其二,文本编码器换成了 GPT-OSS,一个 20B 的混合专家模型、约 3B 激活参数,替掉了常见的冻结 CLIP/T5 组合。训练采用混合分辨率(512、768、1024 见方,外加 1:2 到 2:1 的纵横比),使模型在推理时能泛化到 1440 见方,尽管它并未直接在该尺寸上训练。
后训练管线还加了一轮基于分类体系提示集(Lens-RL-8K)的强化学习,以及一个蒸馏步骤,产出 4 步采样的 Lens-Turbo。
关键结果
- GenEval:0.525(20 步模型),0.519(4 步 Turbo)——足够接近,说明蒸馏几乎不掉质量。
- OneIG(英文):0.557(20 步)对 0.554(Turbo)。
- LongText(英文):0.930,CVTG(NED):0.937——文字渲染成绩强,而这正是密集描述最该发力的地方。
- 训练算力:约 192K 张 A100 GPU 小时,论文称为 Z-Image 约 314K 张 H800 GPU 小时的 ~19.3%。
- 单 H100 延迟:3.15 秒生成一张 1024 见方、20 步图像;Turbo 的 4 步仅 0.84 秒。
- 参数量:扩散骨干 38 亿,对比模型为 60 亿+。
它对竞品的基准领先幅度并不大——Lens 没有宣称霸榜。它主张的是「以零头成本做到持平」,这是另一种、也可能更有用的结论。
局限与存疑
19.3% 这个算力数字跨了不同硬件(A100 对 H800),且只跟 Z-Image 单一对手比,所以它是一个示意性比例,而非受控的效率基准;复现它还得有 GPT-4.1 级别的标注器,而这本身就是头条数字藏起来的一笔不小成本。绝对分数(GenEval 0.525)有竞争力但非最先进,因此「追平 60 亿+ 模型」应理解为「同一区间」,而非「胜过它们」。Lens 全程只用英文描述训练,却报告了多语言生成能力——这是个耐人寻味的迁移效应,但论文更多是定性展示而非定量验证。此外,与所有闭源数据的模型发布一样,Lens-800M 的构成与授权虽有描述却无法公开复刻,独立复现因此受限。
常见问题
Lens 为什么比其他文生图模型更省训练算力?
Lens 把效率主要归功于密集描述:它在 Lens-800M 上训练,8 亿张图每张都配一条约 109 词的 GPT-4.1 描述。更丰富的逐图监督意味着这个 38 亿模型只需远少的 GPU 小时——约 192K 张 A100 小时,论文称为 Z-Image 算力的 ~19.3%——就能达到相当质量。
Lens 和更大的模型比表现如何?
Lens 以 38 亿参数在 GenEval 拿 0.525、OneIG(英文)拿 0.557,处在 60 亿+ 模型的同一区间,而非明显胜出。它最强的项是文字渲染:LongText 0.930、CVTG(NED)0.937。
Lens 推理有多快?
Lens 在单张 NVIDIA H100 上以 20 步采样生成一张 1024 见方图像耗时 3.15 秒。蒸馏的 Lens-Turbo 版只用 4 步、0.84 秒就能完成,基准分数几乎不变。
Lens 用了什么架构和文本编码器?
Lens 是 48 块的 MMDiT 潜空间扩散 Transformer,用 FLUX.2 语义 VAE 作分词器、用 GPT-OSS(20B MoE、约 3B 激活参数)作文本编码器,采用混合分辨率训练并能泛化到 1440 见方图像。
一句话:Lens 押注的是「更长的描述,而非更大的模型」才是文生图质量最便宜的路径。阅读 arXiv 原文。