MMSkills:给通用视觉智能体的多模态技能包
MMSkills 把流程、状态卡、关键帧打包成可复用技能,在 OSWorld 上把 8B 小模型从 10.78% 翻倍到 25.40%,235B 模型从 21.34% 升到 39.17%。
快速答案
MMSkills 把一个可复用的智能体技能表示成「多模态技能包」——文字流程,加运行时状态卡,加多视角关键帧——让视觉智能体按需加载相关技能包。在 OSWorld 上,它把 Qwen3-VL-235B 从 21.34% 提升到 39.17%,把小得多的 Qwen3-VL-8B-Instruct 从 10.78% 提到 25.40%,小模型直接翻倍。前沿模型也受益:Gemini 3.1 Pro 从 44.08% 升到 50.11%,Gemini 3 Flash 从 36.65% 升到 47.97%。工作来自上海交通大学,联合小红书与东南大学。
纯文字技能为什么不够
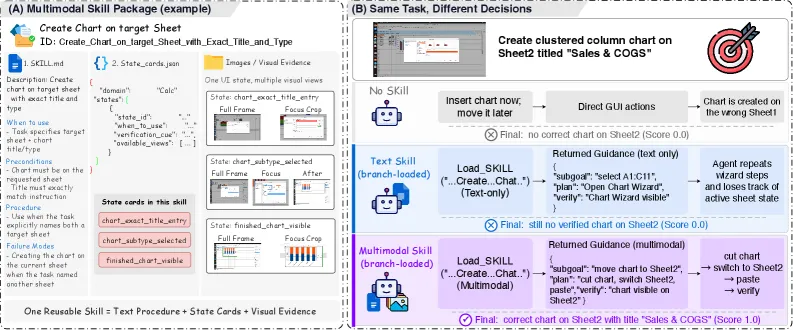
多数智能体的「技能」或「记忆」系统把操作存成文字:点这里,输入这个,再提交。对视觉智能体这套会失灵,因为难点很少在动作本身,而在读懂屏幕。智能体得识别自己当前处在哪个状态,判断上一步到底成没成,还要捕捉到「弹窗打开了」或「保存失败了」的视觉线索。文字流程没法编码「文件选择器长这样」或「这个角标变绿就说明做完了」。MMSkills 的判断是:视觉控制的程序性知识必须携带视觉证据,而不只是指令。
一个多模态技能包里有什么
每个 MMSkills 技能包打包三样东西。文字流程是有序的计划——步骤及其前置条件。状态卡描述智能体将经过的运行时状态,让它把当前屏幕匹配到已知检查点,而不是瞎猜。多视角关键帧是锚定在这些状态上的截图——进度、成功或失败的视觉证据。三者合起来回答的不只是「我该做什么」,还有「我在哪、做对没、怎么算做完」。技能包被设计成状态条件化且紧凑,这对下一部分很关键。
技能包怎么造、怎么用
MMSkills 不靠手写,而是从公开交互轨迹里自动蒸馏技能包——它挖掘 OpenCUA,用 4205 条 Ubuntu 和 3157 条 macOS 轨迹为桌面基准提炼技能。结果是在 OSWorld 的 360 个测试用例上得到 247 个独立技能包,macOSWorld 的 143 个用例上 248 个,再加 VAB-Minecraft 的 24 个和超级马里奥的 10 个。推理时,把所有技能包塞进提示词会撑爆上下文。MMSkills 改用分支加载智能体:只检索并加载与当前状态相关的那条技能包分支,让智能体查阅多模态证据,而不必每一步都为全部技能买单。
关键结果
- OSWorld,Qwen3-VL-235B: 成功率从 21.34% 到 39.17%,约 17.8 个百分点的绝对提升,是报告中单项最大涨幅。
- OSWorld,Qwen3-VL-8B-Instruct: 10.78% 到 25.40%,小开源模型成功率翻倍有余。
- OSWorld,Gemini 3.1 Pro: 44.08% 到 50.11%,说明对强前沿模型仍有效。
- OSWorld,Gemini 3 Flash: 36.65% 到 47.97%,快速档约 11 个百分点提升。
- VAB-Minecraft,Qwen3-VL-8B-Instruct: 23.28% 到 38.79%,收益不只在 GUI,也迁移到游戏环境。
- 覆盖面: 由 4205 条 Ubuntu + 3157 条 macOS 的 OpenCUA 轨迹构建出 247(OSWorld)和 248(macOSWorld)个技能包,跨四个基准评测(25 页、8 图、8 表)。
为什么现在重要
实话实说:这对廉价模型是强结果,对最强模型只是中等结果。8B 模型从 10.78% 到 25.40% 才是头条——它意味着一个小而可部署的智能体,能借来自己永远学不会的程序性能力,而这正是成本敏感的 GUI 自动化所在之处。对 Gemini 3.1 Pro,6 个点的提升真实但偏小,暗示前沿模型内部已经掌握了大部分此类知识。更大的赌注——智能体技能应当是多模态产物而非文字片段——才是值得关注的部分,因为它把「智能体记忆」从一份笔记重新定义成一个结构化、有视觉接地的技能库。
局限与存疑
技能包从既有轨迹里挖出来,所以技能库继承的就是源数据覆盖的范围——OpenCUA 里没先例的任务就没有技能包,论文也没声称能为真正全新的工作流凭空造技能。覆盖还很不均衡:OSWorld 有 247 个包,而超级马里奥只有 10 个,所以游戏结果建在很薄的技能库上,应谨慎解读。基准是 GUI 控制和游戏,不是开放网页或物理任务,因此在这四者之外的泛化未经证明。检索质量是隐性依赖——加载错分支会误导智能体——而论文的论述高度依赖分支加载器工作良好,这一点单从结果很难审计。
常见问题
MMSkills 一句话是什么?
MMSkills 是一个框架,把可复用的视觉智能体技能变成多模态技能包——文字流程、运行时状态卡和多视角关键帧——智能体按需加载,用来读屏幕、跟踪进度、从失败中恢复。
MMSkills 把 OSWorld 成绩提升了多少?
在 OSWorld 上,它把 Qwen3-VL-235B 从 21.34% 提到 39.17%,Qwen3-VL-8B-Instruct 从 10.78% 到 25.40%,Gemini 3.1 Pro 从 44.08% 到 50.11%,Gemini 3 Flash 从 36.65% 到 47.97%。
MMSkills 为什么用关键帧而不只是文字指令?
因为视觉智能体的瓶颈在感知而非动作。关键帧和状态卡给智能体提供视觉证据,让它识别当前状态、确认某一步是成是败——这是纯文字流程编码不了的。
MMSkills 的技能包从哪来?
它们从公开交互轨迹里自动挖掘——来自 OpenCUA 的 4205 条 Ubuntu 和 3157 条 macOS 轨迹——为 OSWorld 产出 247 个、为 macOSWorld 产出 248 个技能包,而非手工编写。
MMSkills 只对小模型有用吗?
不只,但对小模型帮助最大。较小的 Qwen3-VL-8B 在 OSWorld 上成功率大致翻倍,而 Gemini 3.1 Pro 这类强前沿模型只涨约 6 个点,说明它们内部已握有大部分此类程序性知识。
一句话:给视觉智能体的技能应当带图,而不只是步骤。阅读 arXiv 原文。