AI Agents · Multimodal Models · Vision-Language-Action
MMSkills: Multimodal Skill Packages for General Visual Agents
MMSkills packages textual procedures, runtime state cards, and keyframes into reusable skills for visual agents, lifting Qwen3-VL-235B from 21.34% to 39.17% on OSWorld and a small 8B model from 10.78% to 25.40%.
Quick answer
MMSkills represents a reusable agent skill as a multimodal package — a textual procedure plus runtime state cards and multi-view keyframes — and lets a visual agent load the relevant package on demand. On OSWorld it lifts Qwen3-VL-235B from 21.34% to 39.17% and the much smaller Qwen3-VL-8B-Instruct from 10.78% to 25.40%, more than doubling the small model. Frontier models gain too: Gemini 3.1 Pro rises from 44.08% to 50.11% and Gemini 3 Flash from 36.65% to 47.97%. The work comes from Shanghai Jiao Tong University with Xiaohongshu and Southeast University.
The problem with text-only agent skills
Most agent “skill” or “memory” systems store a recipe as text: click here, then type this, then submit. That breaks for a visual agent because the hard part is rarely the action — it is reading the screen. The agent has to recognize which state it is in, decide whether the last step actually worked, and spot the visual cue that says a dialog opened or a save failed. A text procedure cannot encode “the file picker looks like this” or “you are done when this badge turns green.” MMSkills’ bet is that procedural knowledge for visual control has to carry visual evidence, not just instructions.
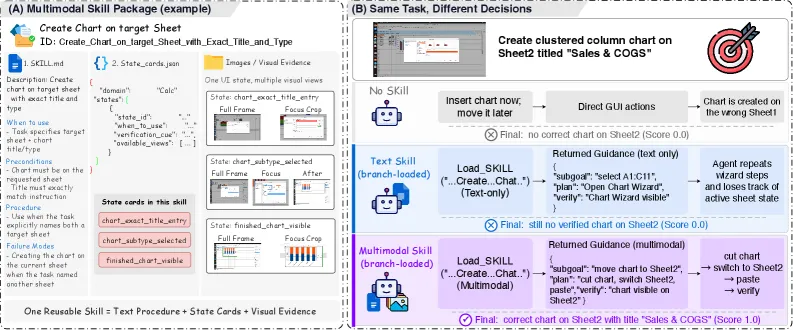
What is inside a multimodal skill package
Each MMSkills package bundles three parts. The textual procedure is the ordered plan — the steps and their preconditions. The state cards describe the runtime states the agent will pass through, so it can match the current screen to a known checkpoint instead of guessing. The multi-view keyframes are screenshots anchored to those states — visual evidence of progress, success, or failure. Together they answer not just “what do I do” but “where am I, is it working, and how will I know it’s done.” The packages are state-conditioned and compact by design, which matters for the next part.
How packages are built and consumed
MMSkills derives packages automatically from public interaction trajectories rather than hand-authoring them — it mines OpenCUA, using 4,205 Ubuntu and 3,157 macOS trajectories to distill skills for the desktop benchmarks. That yields 247 unique packages over OSWorld’s 360 test cases and 248 over macOSWorld’s 143 cases, plus 24 packages for VAB-Minecraft and 10 for Super Mario Bros. At inference, a naive approach would dump every package into the prompt and blow the context window. Instead MMSkills uses a branch-loaded agent: it retrieves and loads only the package branch relevant to the current state, so the agent consults multimodal evidence without paying for all of it on every step.
Key results
- OSWorld, Qwen3-VL-235B: 21.34% to 39.17% success — a ~17.8-point absolute gain, the largest single jump reported.
- OSWorld, Qwen3-VL-8B-Instruct: 10.78% to 25.40%, more than doubling a small open model’s success rate.
- OSWorld, Gemini 3.1 Pro: 44.08% to 50.11%, showing the method still helps a strong frontier model.
- OSWorld, Gemini 3 Flash: 36.65% to 47.97%, an ~11-point gain on a fast tier.
- VAB-Minecraft, Qwen3-VL-8B-Instruct: 23.28% to 38.79%, so the gains are not GUI-only — they carry to a game environment.
- Coverage: built from 4,205 Ubuntu + 3,157 macOS OpenCUA trajectories into 247 (OSWorld) and 248 (macOSWorld) skill packages, evaluated across four benchmarks (25 pages, 8 figures, 8 tables).
Why this matters now
The honest read: this is a strong result for cheap models, and a modest one for the best models. The 8B model going from 10.78% to 25.40% is the headline — it means a small, deployable agent can borrow procedural competence it could never learn on its own, which is exactly where cost-sensitive GUI automation lives. For Gemini 3.1 Pro the 6-point gain is real but suggests frontier models already carry much of this knowledge internally. The broader bet — that agent skills should be multimodal artifacts, not text snippets — is the part worth watching, because it reframes “agent memory” from a notes file into a structured, visually-grounded library.
Limits and open questions
The packages are mined from existing trajectories, so the skill library inherits whatever the source data covers — a task with no precedent in OpenCUA gets no package, and the paper does not claim it can invent skills for genuinely novel workflows. Coverage is also lopsided: 247 packages for OSWorld versus 10 for Super Mario Bros, so the game results rest on a thin library and should be read cautiously. The benchmarks are GUI control and games, not open-ended web or physical tasks, so generalization is unproven outside these four. Retrieval quality is the quiet dependency — loading the wrong branch would mislead the agent — and the paper’s framing leans on the branch loader working well, which is hard to audit from results alone.
FAQ
What is MMSkills in one sentence?
MMSkills is a framework that turns reusable visual-agent skills into multimodal packages — a textual procedure, runtime state cards, and multi-view keyframes — that an agent loads on demand to read the screen, track progress, and recover from failure.
How much does MMSkills improve OSWorld scores?
On OSWorld it raises Qwen3-VL-235B from 21.34% to 39.17%, Qwen3-VL-8B-Instruct from 10.78% to 25.40%, Gemini 3.1 Pro from 44.08% to 50.11%, and Gemini 3 Flash from 36.65% to 47.97%.
Why does MMSkills use keyframes instead of just text instructions?
Because a visual agent’s bottleneck is perception, not action. Keyframes and state cards give the agent visual evidence to recognize its current state and confirm whether a step succeeded or failed — something a text-only procedure cannot encode.
Where do MMSkills packages come from?
They are mined automatically from public interaction trajectories — 4,205 Ubuntu and 3,157 macOS trajectories from OpenCUA — yielding 247 packages for OSWorld and 248 for macOSWorld, rather than being written by hand.
Does MMSkills only help small models?
No, but it helps them most. The smaller Qwen3-VL-8B roughly doubles its OSWorld success, while strong frontier models like Gemini 3.1 Pro gain a smaller ~6 points, suggesting they already hold much of this procedural knowledge.
One line: skills for visual agents should carry pictures, not just steps. Read the original paper on arXiv.