感知还是偏见:多模态大模型能看穿性格的第一印象吗?
MM-OCEAN 检验多模态大模型是否真用视频证据支撑性格评分。27 个模型里,51.3% 的「答对」评分依据的却是错误线索,最强模型也只有 33.5% 的判断真正落地到证据。
快速答案
MM-OCEAN 证明:多模态大模型多半是靠第一印象猜性格,而非真读证据。在 27 个模型(13 闭源、14 开源)上,平均偏见率(Prejudice Rate)高达 51.3%——超过一半「评对了」的大五人格分,根本没有锚定到它本该使用的行为线索上。评分、解释、落地三者全部一致的完整成功率平均只有 10.4%,即便最强的 Gemini 3 Flash 也只到 33.5%。
「有据可依的人格推理」要求什么
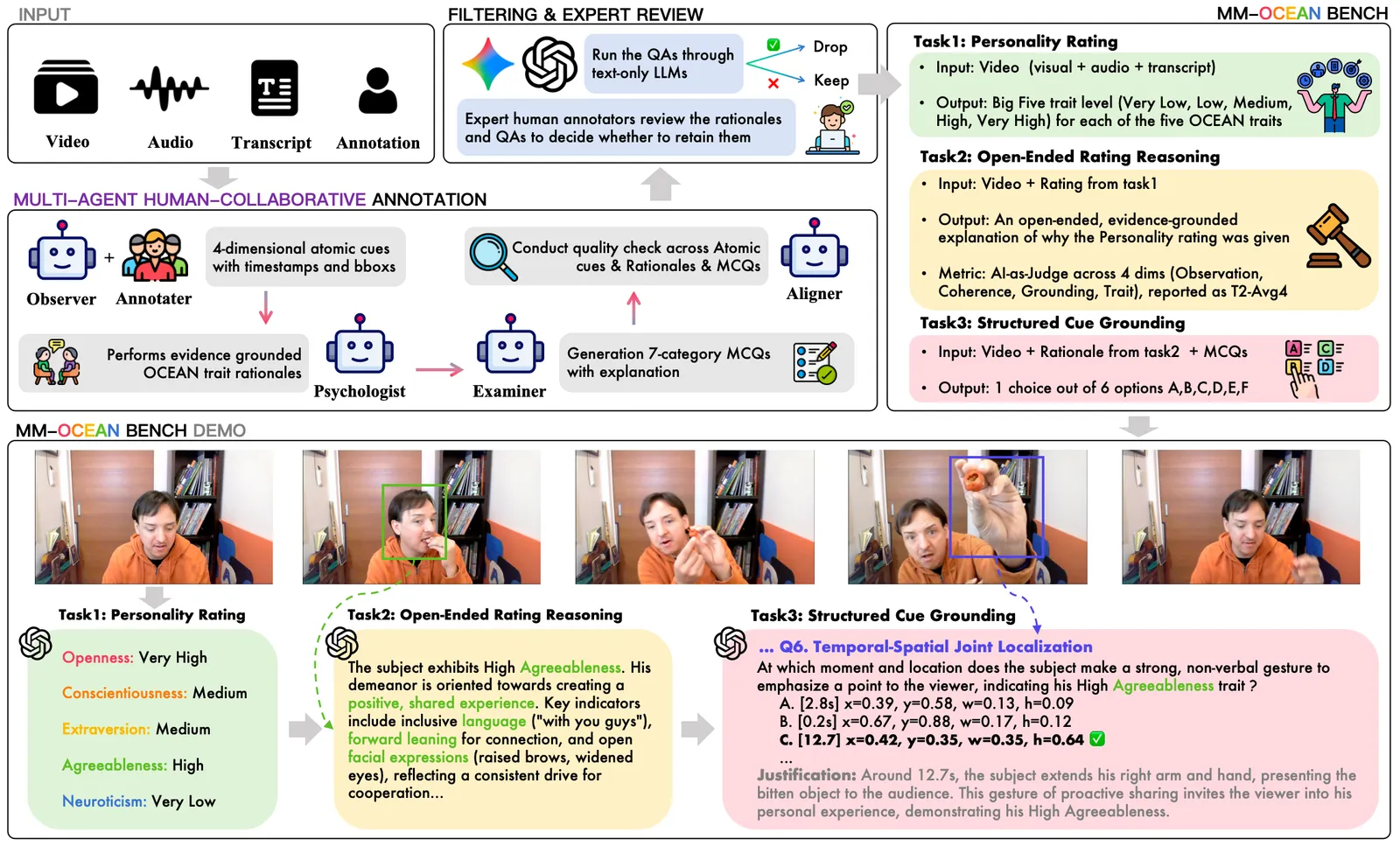
论文把表观人格判断形式化为一个任务,叫「有据可依的人格推理」(Grounded Personality Reasoning, GPR),要求模型同时产出三个互相关联的输出:
- T1 评分: 对大五人格每个维度(开放性、尽责性、外向性、宜人性、神经质)给出 1-5 的有序分数。
- T2 推理: 一段开放解释,必须引用具体可观察的行为,而不是空泛感觉。
- T3 落地: 结构化选择题,把判断钉在具体线索上——微表情、空间位置、时序因果链等。
核心立场是:答对了但理由错了,就算失败。一个嘴上说「高度外向」却指不出是哪个微笑、哪个手势、哪段声音能量支撑这判断的模型,只是在套刻板印象,而非在感知。GPR 就是为抓住这一点而设计的。
MM-OCEAN 里有什么
MM-OCEAN 收录 1,104 段视频,取自 ChaLearn First Impressions V2 数据集,配 5,320 道选择题(平均每段约 4.8 题),以及约 13,500 条人工核验的原子级行为观察,覆盖四个感知通道。它由一条多阶段人机协作管线产出:观察者智能体提出线索,人工核验,心理学家智能体把线索映射到人格维度,出题智能体写题,最后再用「文本泄漏过滤」加专家复审,剔除任何仅凭文字转录就能答出的题。判定标签上的标注者一致率为 77%。
那道文本泄漏过滤比听起来更关键。多模态基准的一个老毛病是:号称考「视觉」的题,其实偷偷靠文字就能做对。把这类题滤掉,MM-OCEAN 才真正逼模型去看。
它测量的四种失败模式
MM-OCEAN 不报单一准确率,而是用四个诊断率,把模型「怎么错」拆开:
- 偏见率(PR): 评分对、线索错——这是核心发现。
- 虚构率(CR): 听起来像样的理由,却建立在不准的证据上。
- 整合失败率(IR): 线索找对了,却推出了错误的人格结论。
- 整体落地率(HR): 唯一的成功状态——评分、推理、落地全对且一致。
这套拆解才是论文真正的贡献。一个单一排行榜分数会掩盖一个事实:高评分准确率和真正的感知,几乎是脱钩的。
关键结果
- 平均偏见率 51.3%(27 个模型):大多数评对的人格分,并没有锚定在正确的行为证据上。
- 平均整体落地率 10.4%: 整个领域,模型大约每十次才完整地把判断落到证据上一次。
- HR 区间 0 到 33.5%: 最弱的模型一题没落地;Gemini 3 Flash 以 33.5% HR、17.2% PR 领先。
- 闭源胜出主要靠落地,而非评分: 在评分(T1)上闭源仅领先 5.6 个百分点,在落地(T3)上却领先 26.6 个百分点——差距压倒性地在于能否定位证据,而非能否输出一个看似合理的分。
- 视觉是瓶颈: 空间定位平均准确率仅 30.7%、微表情检测 34.6%,而时序因果推理达 64.8%。模型「论行为」远强于「看行为」。
- 开源里最强是 Qwen3.5-397B,HR 为 15.9%,但 PR 高达 41.5%,比闭源领头者偏见得多。
为什么值得关注
表观人格预测已经被用在招聘初筛和广告定向里,而一个让人安心的假设是:大五人格评得好的模型,就是在「读懂」这个人。MM-OCEAN 表明这假设大体是假的:分可以评对,底下的推理却是刻板印象。这不只是准确率问题,更是公平问题——一个根本没真正端详过那张脸、就判定其外向程度的系统,会把训练分布里编码的偏见原样带出。把「落地」做成一等的、单独计分的硬指标,这个基准就给修复它定了一个具体靶子。
局限与存疑
诚实的保留意见是真实存在的。MM-OCEAN 测的是「表观」人格——一个人在 15 秒、单人、英语片段里给人的印象——而非真实的自陈人格,所以模型「错」的地方,人类也可能同样错。T2 的推理质量由 AI(GPT-4o-mini)而非人来评判,这把那个裁判自身的盲区也带了进来。片段短、单一语言、且取自同一个数据集,跨文化与长视频的感知都没被测到。而且这篇论文是诊断性的,不是开方子:它清楚地展示了偏见鸿沟,却没提出训练方法去弥合,把最显然的下一问——落地能力能被训练出来吗——完全敞着。
常见问题
MM-OCEAN 基准到底在测什么?
它测一个多模态大模型能否用正确的可观察证据来支撑大五人格评分,而不只是产出一个看似合理的分。它把评分、自由文本推理、结构化线索落地一起计分,所以「答对但线索错」算失败。
MM-OCEAN 里的偏见率是什么?
偏见率是「评对的人格分里,没有锚定到正确行为线索」的比例——也就是「答案对、理由错」。27 个模型上平均为 51.3%,意味着超过一半的正确评分,实质上是靠第一印象的瞎蒙。
MM-OCEAN 上哪个模型表现最好?
Gemini 3 Flash 以 33.5% 的整体落地率、17.2% 的偏见率领先。没有模型超过 34% 的完整落地,全领域平均仅 10.4%,所以连领头者多数时候也无法完整地把判断落到证据上。
为什么落地对多模态大模型比评分难?
因为评分只需要一个看似合理的分,落地却要模型定位具体的视觉证据。闭源对开源的差距在评分上是 5.6 个百分点,在落地上却是 26.6 个百分点,而最难的几类都是感知性的——空间定位 30.7%、微表情检测 34.6%。
一句话:把人格评对很容易,把它「评对得有道理」才是多模态大模型崩盘的地方。阅读 arXiv 原文。