PhysBrain 1.0:把人类视频编译成机器人的物理先验
PhysBrain 1.0 把人类第一视角视频编译成物理问答预训练 VLM,再适配成机器人策略:真实 Franka 抓取 50 次试验从 47.1% 提到 63.3%(对比 pi0.5)。
快速答案
PhysBrain 1.0 把大规模人类第一视角视频编译成结构化的物理问答监督,先用它预训练一个视觉语言模型(VLM),再把这个模型适配成机器人策略。在真实 Franka 操作上,它把单物体蔬菜抓取从 47.1% 提到 63.3%、把长程语义指令任务从 31.0% 提到 45.0%(各 50 次试验,对比 pi0.5 基线)。核心赌注是:物理理解可以从人类已经拍好的海量视频里挖出来,而不必依赖昂贵的遥操作机器人数据。
它瞄准的数据瓶颈
机器人学习一直缺数据。遥操作示范采集慢、成本高,而且每换一种机器人形态都得重新采。人类第一视角视频——拍人做日常物理任务的第一人称画面——既多又免费,但它没有机器人能直接照抄的动作标签。PhysBrain 1.0 的主张是:有用的部分根本不需要动作标签,而是其中的物理理解——场景构成、空间布局、物体动态,以及动作如何在空间里展开。这种理解是一种先验,可以烤进 VLM 再带进策略里。
编译器式管线如何工作
系统把原始视频当成源代码,分三层”编译”成监督信号。第一层抽取结构化的场景元信息——场景元素、空间关系、动作执行——存成 JSON 表示。第二层用 Depth Anything v3(DA3 嵌套深度模型)做深度感知的空间增强,让”在前面""更近”这类关系扎根于真实几何,而不是从二维像素里猜。第三层从这份结构化元数据生成有物理依据的问答对,作为 VLM 的训练监督。
数据取自现有的第一视角语料——Ego4D、EgoDex、EPIC 等——再加上 FineVision 这类通用多模态数据,以保住广义能力。VLM 在这套物理问答上训练完后,再适配成机器人策略。这里有一处坦诚的设计张力:灾难性遗忘。把 VLM 压进底层控制通常会侵蚀它的通用视觉语言能力,报告把”保住这些能力”明确列为适配阶段的目标,而非事后补救。
关键结果
- 单物体抓取: PhysBrain 1.0 在真实 Franka 单物体蔬菜抓取上 50 次试验从 47.1% 提到 63.3%,对比 pi0.5 基线,约 16 个百分点的绝对提升。
- 长程任务: 长程语义指令任务 50 次试验从 31.0% 提到 45.0%,同一基线——长程是大多数策略崩溃的地方,这 14 个百分点更能说明问题。
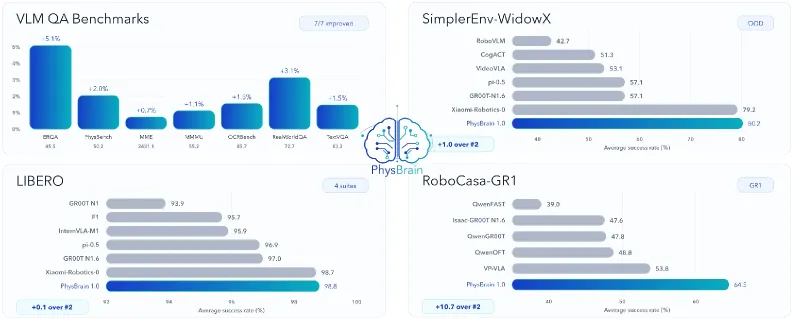
- 评测广度: 报告称在 VLM 侧(ERQA、PhysBench、MME、MMMU、OCRBench、RealWorldQA、TextVQA)与 VLA 侧(SimplerEnv-WidowX、SimplerEnv-GoogleRobot、LIBERO、RoboCasa-GR1)均有强表现,并强调 SimplerEnv 上的域外强度。
- 深度接地: 空间关系靠 Depth Anything v3 锚定,而非从平面图像推断,这才让问答能针对深度感知的关系。
为什么现在重要
VLA 模型是机器人领域最热的路线,而行业最硬的约束是数据,不是架构。PhysBrain 1.0 是一次具体、可量化的尝试:把互联网上海量的人类视频转化成机器人策略真能用的东西——不靠遥操作设备。“视频即编译器”这个框架是真正新的点子:它不模仿视频里的动作(因为形态不同会失败),而是模仿物理理解,后者迁移得更干净。如果这套提升能超出 Franka 站住脚,它就是一个比”一条机械臂一条机械臂地采示范”便宜得多的数据飞轮。
局限与存疑
头条的真实世界数字来自单一 Franka 平台、对单一基线(pi0.5)的 50 次试验。50 次对于两位数百分点的结论是小样本,单一形态也让真实世界里的跨机器人迁移仍未证实。这是技术报告而非同行评审论文:广泛的基准胜绩(ERQA、PhysBench、LIBERO、RoboCasa)在我们能核到的正文里没有逐项分数,所以”最先进”的说法在表格公开前应视作作者主张。灾难性遗忘被点名为设计目标,但报告没量化适配后通用 VLM 能力到底保住了多少。管线还会继承源语料的偏置——Ego4D 和 EPIC 偏厨房与家居任务,这些先验能延伸到工业或灵巧操作多远尚不清楚。
常见问题
PhysBrain 1.0 是什么?
PhysBrain 1.0 是一套系统,把人类第一视角视频编译成结构化的物理问答数据,用它预训练视觉语言模型,再把该模型适配成机器人操作策略。它提供了一条不必采集昂贵遥操作数据、就能改进机器人策略的路线。
PhysBrain 1.0 没有动作标签怎么用人类视频?
PhysBrain 1.0 不模仿视频里的动作。它抽取物理理解——场景元素、空间关系、物体动态、深度感知几何——并转成问答监督。这种物理先验能迁移给机器人,即便人类的具体动作不能。
PhysBrain 1.0 把机器人操作提升了多少?
在真实 Franka 任务上 50 次试验,PhysBrain 1.0 把单物体抓取从 47.1% 提到 63.3%、把长程语义指令从 31.0% 提到 45.0%,均对比 pi0.5 基线。
Depth Anything v3 在 PhysBrain 1.0 里起什么作用?
PhysBrain 1.0 用 Depth Anything v3(DA3 嵌套深度模型)做深度感知的空间增强,让生成的空间关系问题扎根于真实三维几何,而不是从二维图像里猜。
一句话:从人类视频而非机器人遥操作中挖物理理解,一个 VLM 就能把这份先验带进可用的策略。阅读 arXiv 原文。