Vision-Language-Action · Robotics · Multimodal Models
PhysBrain 1.0: Turning Human Video into Physical Priors for Robots
PhysBrain 1.0 compiles human egocentric video into physics QA to pretrain a VLM, then adapts it to robot control — lifting Franka grasping from 47.1% to 63.3% over 50 trials versus a pi0.5 baseline.
Quick answer
PhysBrain 1.0 turns large-scale human egocentric video into structured physics question-answer supervision, pretrains a vision-language model (VLM) on it, then adapts that model into a robot policy. On real-world Franka manipulation it lifts single-object vegetable grasping from 47.1% to 63.3% and long-horizon semantic instructions from 31.0% to 45.0% across 50 trials, measured against a pi0.5 baseline. The bet is that physical understanding can be mined from video humans already recorded, rather than from expensive teleoperated robot data.
The data bottleneck it attacks
Robot learning is starved for data. Teleoperated demonstrations are slow and costly to collect, and every new embodiment needs its own. Human egocentric video — first-person footage of people doing everyday physical tasks — is abundant and free, but it has no action labels a robot can copy. PhysBrain 1.0’s claim is that you do not need the action labels to extract the useful part: the physical understanding of scenes, spatial layout, object dynamics, and how actions unfold in space. That understanding is a prior you can bake into a VLM and carry into a policy.
How the compiler pipeline works
The system treats raw video as source code and “compiles” it into supervision in three layers. First it extracts structured scene meta-information — scene elements, spatial relations, and action execution — into a JSON representation. Second it adds depth-aware spatial augmentation using Depth Anything v3 (the DA3 nested depth model), so relations like “in front of” or “closer than” are grounded in real geometry rather than guessed from 2D pixels. Third it generates physically grounded question-answer pairs from that structured metadata, which become training supervision for the VLM.
The data is drawn from existing egocentric corpora — Ego4D, EgoDex, and EPIC among them — plus general multimodal data such as FineVision to keep broad capabilities intact. After the VLM is trained on this physics QA, it is adapted into a robot policy. The honest design tension here is catastrophic forgetting: pushing a VLM into low-level control usually erodes its general vision-language skills, and the report frames preserving those skills as an explicit goal of the adaptation stage rather than an afterthought.
Key results
- Single-object grasping: PhysBrain 1.0 raises real-world Franka single-object vegetable grasping from 47.1% to 63.3% over 50 trials, versus a pi0.5 baseline — a ~16-point absolute gain.
- Long-horizon tasks: On long-horizon semantic instructions it improves from 31.0% to 45.0% across 50 trials, the same baseline — long-horizon is where most policies fall apart, so the 14-point lift is the more telling number.
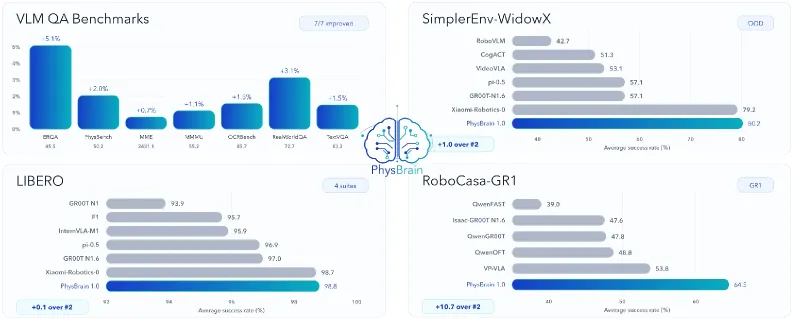
- Breadth of evaluation: The report claims strong results on the VLM side (ERQA, PhysBench, MME, MMMU, OCRBench, RealWorldQA, TextVQA) and the VLA side (SimplerEnv-WidowX, SimplerEnv-GoogleRobot, LIBERO, RoboCasa-GR1), with out-of-domain strength highlighted on SimplerEnv.
- Depth grounding: Spatial relations are anchored with Depth Anything v3 rather than inferred from flat images, which is what lets the QA target depth-aware relations at all.
Why this matters now
VLA models are the hot path in robotics, and the field’s hardest constraint is data, not architecture. PhysBrain 1.0 is a concrete, measurable attempt to convert the internet’s enormous stock of human video into something a robot policy can actually use — without teleoperation rigs. The “video as a compiler” framing is the genuinely new idea: instead of imitating actions from video (which fails because the embodiment differs), it imitates physical understanding, which transfers more cleanly. If the gains hold up beyond Franka, this is a cheaper data flywheel than collecting robot demonstrations one arm at a time.
Limits and open questions
The headline real-world numbers come from 50 trials on a single Franka platform against one baseline (pi0.5). Fifty trials is a small sample for two-digit-percent claims, and a single embodiment leaves cross-robot transfer unproven in the real world. This is a technical report, not a peer-reviewed paper: the broad benchmark wins (ERQA, PhysBench, LIBERO, RoboCasa) are asserted without the per-benchmark scores in the text we could verify, so treat the “state-of-the-art” framing as the authors’ claim until tables are public. Catastrophic forgetting is named as a design target but the report does not quantify how much general VLM capability survives adaptation. And the pipeline inherits the biases of its source corpora — Ego4D and EPIC skew toward kitchen and household tasks, so it is unclear how far the priors stretch to industrial or dexterous manipulation.
FAQ
What is PhysBrain 1.0?
PhysBrain 1.0 is a system that compiles human egocentric video into structured physics question-answer data, pretrains a vision-language model on it, and adapts that model into a robot manipulation policy. It is a route to better robot policies that avoids collecting expensive teleoperated robot data.
How does PhysBrain 1.0 use human video without action labels?
PhysBrain 1.0 does not imitate the actions in the video. It extracts physical understanding — scene elements, spatial relations, object dynamics, depth-aware geometry — and turns that into QA supervision. The physical prior transfers to robots even though the human’s exact motions do not.
How much does PhysBrain 1.0 improve robot manipulation?
On real-world Franka tasks over 50 trials, PhysBrain 1.0 raises single-object grasping from 47.1% to 63.3% and long-horizon semantic instructions from 31.0% to 45.0%, both versus a pi0.5 baseline.
What is the role of Depth Anything v3 in PhysBrain 1.0?
PhysBrain 1.0 uses Depth Anything v3 (the DA3 nested depth model) to add depth-aware spatial augmentation, so the generated questions about spatial relations are grounded in real 3D geometry instead of being guessed from 2D images.
One line: mine physical understanding from human video, not robot teleoperation, and a VLM can carry that prior into a working policy. Read the original report on arXiv.