Vision-Language-Action · Robotics · AI for Science
LabVLA: A VLA Model for Scientific Lab Robots
LabVLA trains a Qwen3-VL-4B backbone plus DiT action expert on laboratory workflows and reports 71.1% ID and 70.0% OOD success on LabUtopia.
Quick answer
LabVLA is a vision-language-action model aimed at laboratory robot work, not household tabletop demos. The paper builds RoboGenesis, a simulation and data engine for lab workflows, then trains a Qwen3-VL-4B-Instruct backbone with FAST action token pretraining and a flow-matching DiT action expert. On LabUtopia, LabVLA reports 71.1% average success in distribution and 70.0% out of distribution, beating the next best policy, pi0, by 7.8 and 6.8 percentage points.
Why this paper is different from another VLA benchmark
The useful distinction is domain. Most VLA policies learn from household, office, or general tabletop manipulation. Scientific labs contain fixed protocols, transparent liquids, fragile instruments, and tasks where doing the right action in the wrong order can invalidate the experiment. A robot that can move a mug is not automatically ready to pour reagent into a beaker or place labware on a heating plate.
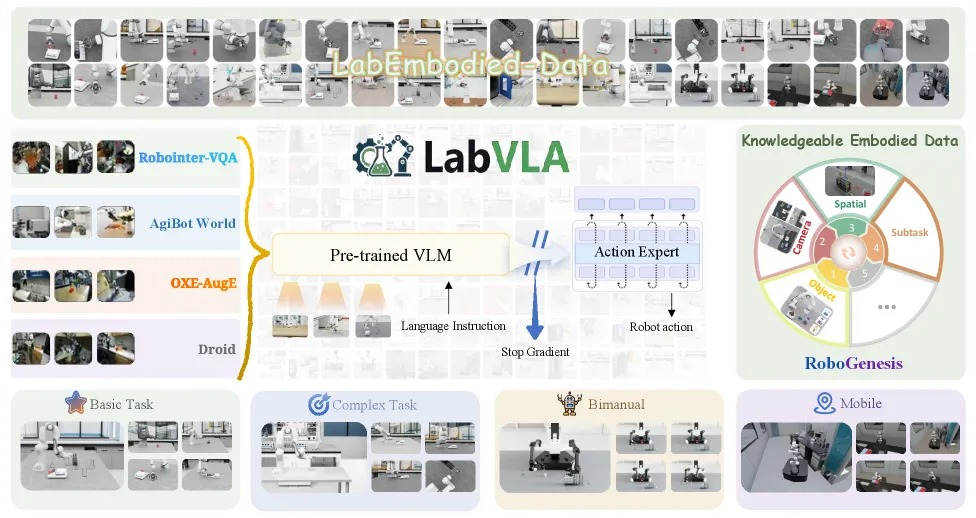
LabVLA frames the bottleneck as data plus embodiment. The model architecture matters, but the paper’s bet is that laboratory execution needs protocol-conditioned demonstrations across robot profiles. RoboGenesis supports 16 robot platforms, builds a 2,947-asset LabAssetLibrary, generates 10,000 lab scenes, decomposes instructions into atomic skills, applies six-axis domain randomization, validates rollouts, and exports only successful demonstrations with structured annotations.
The model recipe
LabVLA couples a pretrained VLM to a DiT action expert. The VLM reads language and multiview images. The action expert emits robot actions. A stop-gradient path, described as knowledge insulation, tries to prevent the action loss from damaging the language and visual knowledge already inside the backbone.
The training has two stages. FAST action token pretraining first makes the Qwen3-VL-4B backbone action-aware before continuous control is learned. Flow-matching posttraining then attaches the DiT action expert. This is a pragmatic choice: make the model understand action structure before asking it to output continuous robot behavior.
Key results
- LabUtopia average: LabVLA reaches 71.1% in-distribution and 70.0% out-of-distribution success across six laboratory tasks.
- Best baseline gap: the next best average is pi0 at 63.3% ID and 63.2% OOD, so LabVLA leads by 7.8 and 6.8 points.
- OOD stability: LabVLA drops only 1.1 points from ID to OOD, which supports the paper’s claim that RoboGenesis randomization helps generalization.
- Task split: LabVLA scores 100% on Press Button ID, 65.0% or 65.8% on Open Door, and 49.2% or 48.3% on Pick Up.
- Hard failure mode: Pour Liquid remains weak in the LabUtopia Table 2 setting; LabVLA reaches 43.3% ID and 34.2% OOD, and no baseline exceeds 50% on that simulated task column.
- Real Franka transfer: the physical evaluation uses four tasks, 50 rollouts per setting, and a Franka platform. LabVLA scores roughly 76-92% across Shake Liquid, Pour Liquid, Magnetic Stir, and Stopper Plug/Unplug settings, but DreamZero or pi0.5 can match or beat it on some rows.
What the result actually proves
The paper shows that lab-specific data improves a VLA policy under a lab simulation benchmark. It does not prove autonomous wet-lab science. The robot is executing configured workflows, not deciding which experiment should be run, noticing contamination, negotiating safety exceptions, or interpreting surprising scientific results.
That makes the result more credible, not less. The near-term useful system is a protocol executor for constrained lab operations. LabVLA is strongest when read as infrastructure for turning written procedures into robot trajectories under a controlled task distribution.
Limits and open questions
The largest open question is real lab transfer. The Franka results show promising protocol transfer, but they are still four benchtop tasks with 50 rollouts per setting, not a full wet-lab deployment. Transparent liquids, lighting, occlusions, gripper wear, calibration drift, reagent variability, contamination, and safety constraints are exactly where lab robotics gets expensive.
The second caveat is that the benchmark still abstracts away scientific judgment. LabVLA can be valuable if a human or another system has already specified the protocol. It is not evidence that a VLA model can autonomously design, debug, and validate experiments end to end.
FAQ
What is LabVLA?
LabVLA is a vision-language-action model for laboratory robot manipulation. It uses a Qwen3-VL-4B-Instruct backbone and a DiT action expert trained with laboratory workflow data from RoboGenesis.
How well does LabVLA perform on LabUtopia?
LabVLA reports 71.1% average success in distribution and 70.0% out of distribution across six LabUtopia tasks. It beats pi0 by 7.8 points ID and 6.8 points OOD.
What is RoboGenesis in the LabVLA paper?
RoboGenesis is the simulation and data engine used to create lab scenes, generate workflows from atomic skills, run 16 supported robot platforms, apply domain randomization, filter failed rollouts, and export annotated demonstrations.
How did LabVLA transfer to real Franka experiments?
The real-robot study uses four Franka tasks with 2-4 atomic skills and 50 rollouts per setting. LabVLA lands in the 70-92% range across the reported settings, but it does not dominate every row against DreamZero and pi0.5.
Does LabVLA prove wet-lab autonomy?
No. It supports protocol execution under constrained tasks. It does not prove safe autonomous experiment design, contamination handling, unexpected-result interpretation, or cross-lab robustness.
What is LabVLA’s biggest limitation?
Pouring liquid remains the clearest weak task, with LabVLA at 43.3% ID and 34.2% OOD. More broadly, the paper is stronger evidence for protocol execution than for fully autonomous scientific discovery.
One line: LabVLA is worth reading because it moves VLA evaluation toward laboratory work, while still making clear that wet-lab autonomy is not solved. Read the original paper on arXiv.