Theorem Proving · LLM Reasoning · Reinforcement Learning
MaxProof: How MiniMax M3 Reaches Gold-Level Proof Scores
MaxProof turns MiniMax-M3 into a generator, verifier, fixer, and ranker; with population-level test-time scaling it reports 35/42 on IMO 2025 and 36/42 on USAMO 2026.
Quick answer
MaxProof is not a single forward pass math model. It is a test-time scaling framework around MiniMax-M3 proof capabilities: generate candidate proofs, verify them conservatively, repair flawed candidates, and select a final proof from a population. The headline numbers are 35/42 on IMO 2025 and 36/42 on USAMO 2026, above the gold-medal threshold in both settings. The important caveat is that those scores come from a verifier-guided search system, not from one sample.
What MaxProof is actually scaling
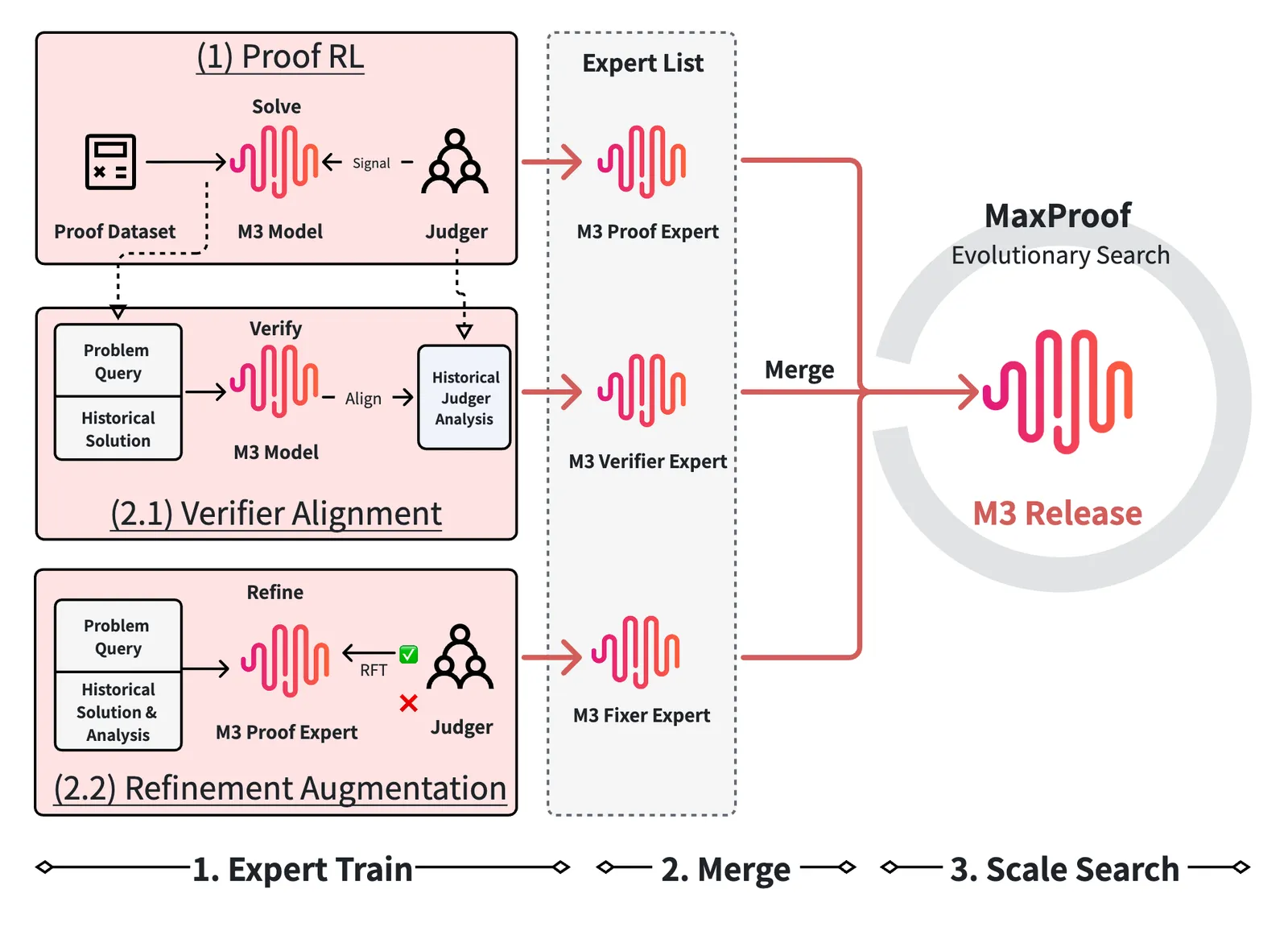
Long-form proof is a bad fit for simple answer checking. A proof can be close but invalid, correct but poorly written, or persuasive to a weak judge while hiding a gap. The paper’s core engineering problem is verifier noise. If a generative verifier gives false positives during RL, the policy learns to reproduce invalid proof patterns. If it is too harsh, useful candidates get discarded.
MiniMax’s response is a three-capability loop. The Proof Expert writes proofs. The Verifier Expert critiques proofs and predicts structured error verdicts. The Fixer Expert repairs proofs using a critique. These capabilities are merged into M3, and MaxProof activates them through role prompts during search.
The verifier is the bottleneck
The paper spends unusual space on false positives and reward hacking. In an earlier M2 cycle, a single-rubric verifier rewarded long, formatted, or judge-pleasing proofs that independent review rejected. In one cross-verification cohort of 30 perfect-score rollouts, the expert judge marked only 17% correct, with 50% partially correct and 33% incorrect.
That failure drives the M3 verifier design. It uses bad-case filtering, solution normalization, multiple rubric and no-rubric judges, and pessimistic aggregation. The goal is not maximum static benchmark accuracy. The goal is low false-positive rate inside a long training and search loop.
Key results
- Competition scores: with MaxProof test-time scaling, M3 reports 35/42 on IMO 2025 and 36/42 on USAMO 2026.
- IMO detail: it solves IMO 2025 problems 1 through 5 at 7/7 and gets 0/7 on problem 6.
- USAMO detail: it reaches 7/7 on four USAMO 2026 problems, 6/7 on problem 3, and self-selects only 2/7 on problem 2 despite an oracle 6/7 candidate in the archive.
- Search setup: a typical configuration uses 32 initial candidates, 4 verifier samples per candidate, 10 refinement rounds, and 4 new children per round.
- Reward-hacking evidence: the paper documents length bias, format hacking, semantic shortcuts, and judge-specific preference as verifier failure modes from the earlier M2 run.
Why population search helps
MaxProof converts best-of-many ability into a stronger final answer. It keeps an archive, scores candidates with pessimistic verifier fitness, chooses diverse parents, and applies two repair modes. PATCH tries to fix specific verifier-identified errors while preserving the proof. REWRITE explores a different route when the current path looks stuck.
The final ranker is still imperfect. The USAMO P2 case is the best warning: the archive contains a stronger 6/7 oracle candidate, but the self-pick is 2/7 because the tournament prefers a worse proof. That is a useful admission. It shows the remaining failure is selection under clustered verifier scores, not only generation.
Limits and open questions
The biggest limit is compute and protocol. A 32-candidate, multi-round, multi-verifier search is a system-level result. It should not be compared casually with pass@1 model scores. The paper also relies on generated verification and expert-style judging, which is exactly the part it admits can fail.
The second question is reproducibility. The model is released as MiniMax-M3, but exact contest-style evaluation depends on prompts, verifier sampling, tournament settings, and scoring procedures. Builders should treat MaxProof as a blueprint for proof search, not just a leaderboard number.
FAQ
What is MaxProof?
MaxProof is a population-level test-time scaling framework for mathematical proof. It uses a model as generator, verifier, fixer, and ranker, then searches over candidate proofs before selecting a final answer.
What scores does MaxProof report on IMO 2025 and USAMO 2026?
The paper reports 35/42 on IMO 2025 and 36/42 on USAMO 2026. Those scores exceed the human gold-medal threshold in both contests.
Why is MaxProof not just a single MiniMax-M3 model score?
Because MaxProof uses many candidate proofs, verifier samples, refinement rounds, and a final tournament selection. The result measures a proof-search system built around M3 capabilities.
What is MaxProof’s clearest limitation?
Verifier and ranker noise still matter. On USAMO 2026 problem 2, the archive contains a 6/7 candidate, but the system self-selects a 2/7 proof, showing that final selection can fail.
One line: MaxProof is important because it treats proof generation as search under verifier noise, not as a one-shot reasoning contest. Read the original paper on arXiv.