Representation Forcing:扔掉 VAE 的统一多模态模型
RF 让统一多模态模型不再依赖冻结 VAE,RF-Pixel 先预测表征 token 再生成像素,GenEval 0.84,MMMU 比 VAE 版本高 4.3 分。
快速答案
Representation Forcing(RF)做出了一个不依赖冻结、单独预训练 VAE 的统一「图像理解 + 生成」模型。它不再从外部隐空间解码像素,而是让 RF-Pixel 先自回归地预测视觉表征 token,把它们留在上下文里,再在同一个主干上跑像素扩散。结果是 GenEval 总分 0.84(加上 LLM 改写提示词为 0.88),在生成上与 VAE 方案持平;同时 MMMU 理解得分 54.2,比在 VAE 隐空间上训练的同架构高出 4.3 分。
它要拆掉的 VAE 瓶颈
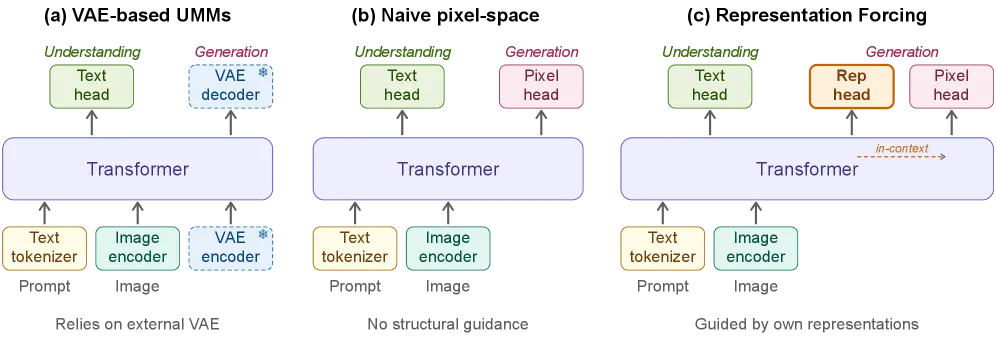
多数统一多模态模型的做法,是在理解主干上「焊」一个生成模块,复用一个冻结的 VAE:文生图扩散跑在某个为重建(而非语义)学出来的隐空间里。这个隐空间本身就是瓶颈——它为压缩像素而优化,因此丢掉了感知模型真正想要的高层结构;又因为它被冻结,统一模型无法重塑它。于是出现了对统一模型的老抱怨:生成能用,但共享表征用于理解时,反而不如一个专门的编码器。
RF 的主张是:你根本不需要这个外部隐空间。只要模型能把「预测好的视觉表征」当作自身原生能力,这些预测就能扛起原本由 VAE 隐空间承担的语义负担,像素也能直接从中生成。
RF-Pixel 怎么工作
架构是一个 mixture-of-transformers:共享自注意力层,但 token 被路由到三个模态专属的前馈专家——理解、表征预测、像素生成各一个。生成在一次前向里分两步:解码器先自回归地吐出视觉表征 token,这些 token 随后留在上下文窗口里,作为条件去驱动一个 flow-matching(x-prediction)目标来产出像素。训练混合三种损失:文本 token 的交叉熵、表征 token 的交叉熵,以及像素的 flow-matching 损失。
值得点名的关键动作是:「representation forcing」逼模型在落笔画像素之前,先确定一份语义规划(表征 token),正如 teacher forcing 逼语言模型确定下一个 token。由于这些 token 也复用于理解,生成和感知共享同一份由模型自己塑造的表征,而不是从重建训练的 VAE 那里继承来的。
关键结果
- GenEval 总分 0.84,配 LLM 改写器为 0.88——按论文报告领先 Show-o2(0.76)、Janus-Pro-7B(0.80)和 BAGEL(0.82)。
- MMMU 理解上,Pixel+RF 模型拿到 54.2,比 VAE+RF 版本的 49.6 高 4.3 分——这是「扔掉 VAE 不只帮生成、也帮感知」最干净的证据。
- DPG-Bench 总分 84.15,落后于专门的文生图系统 Seedream 3.0(88.27)和 Qwen-Image(88.32),这是诚实的差距:RF 追平的是统一模型同行,而非最强的纯生成模型。
- 论文还在 HalluBench、MME、BLINK、RealWorldQA、AI2D、DocVQA、ChartQA 上做了评测,把 RF 定位成一个广谱理解模型,而不是窄用途的生成器。
为什么现在重要
统一多模态模型是 2026 年最热的赛道,而「冻结 VAE」这套设计,是大家照抄却并不真心喜欢的部分。RF 是第一个认真论证「外部生成隐空间可有可无」的工作——一个主干就能学到既能用来生成、又能用来理解的表征。如果它在更大规模上站得住,整条管线都会变简单:不用再单独预训练、托管、同步一个 VAE,要改进的也只剩一份表征,而不是去调和两个隐空间。
局限与存疑
生成差距是真实存在、也没有遮掩的:DPG-Bench 上 84.15 对最强纯文生图模型的约 88,意味着 RF 买到的是架构上的简洁,而非顶尖画质。理解上的头条胜利,是和同架构跑在 VAE 隐空间的版本比出来的——这是公平的消融,但也是个友好的基线:它说明 RF 赢了自家 VAE 版本,不等于它赢过最强的纯理解编码器。每张图前都要预测表征 token,多了一个自回归阶段,推理成本相比纯隐空间扩散很可能更高;而且论文规模相对前沿闭源系统并不大,所以「无 VAE」这一赌注能否在生产规模上成立,仍是未知数。
常见问题
统一多模态模型里的 Representation Forcing 是什么?
Representation Forcing(RF)是一种训练技巧:模型在生成像素之前,先自回归地预测视觉表征 token,并在上下文里复用这些 token 来驱动同一主干内的像素扩散——从而去掉其他统一模型所依赖的冻结 VAE。
RF-Pixel 在 GenEval 上和 Janus-Pro、BAGEL 比如何?
RF-Pixel 报告 GenEval 总分 0.84(加 LLM 改写器为 0.88),领先 Janus-Pro-7B 的 0.80 和 BAGEL 的 0.82,生成总体上与 VAE 方案的统一模型持平。
去掉 VAE 真的能帮到图像理解吗?
按论文的消融,是的:Pixel+RF 模型 MMMU 得 54.2,而同架构在 VAE 隐空间上训练只有 49.6,高 4.3 分,说明模型原生的表征比冻结重建隐空间携带了更多有用语义。
RF-Pixel 是文生图的最强水平吗?
不是。它在 DPG-Bench 上得 84.15,落后于 Seedream 3.0(88.27)和 Qwen-Image(88.32)这类专门的文生图系统。RF 追平的是统一模型同行,而非最强的纯生成模型。
一句话:先预测表征,再画像素,然后就能把 VAE 扔掉。阅读 arXiv 原文。