扩散模型 · 文生图 · Transformer
重新审视扩散 Transformer 的跨层信息路由
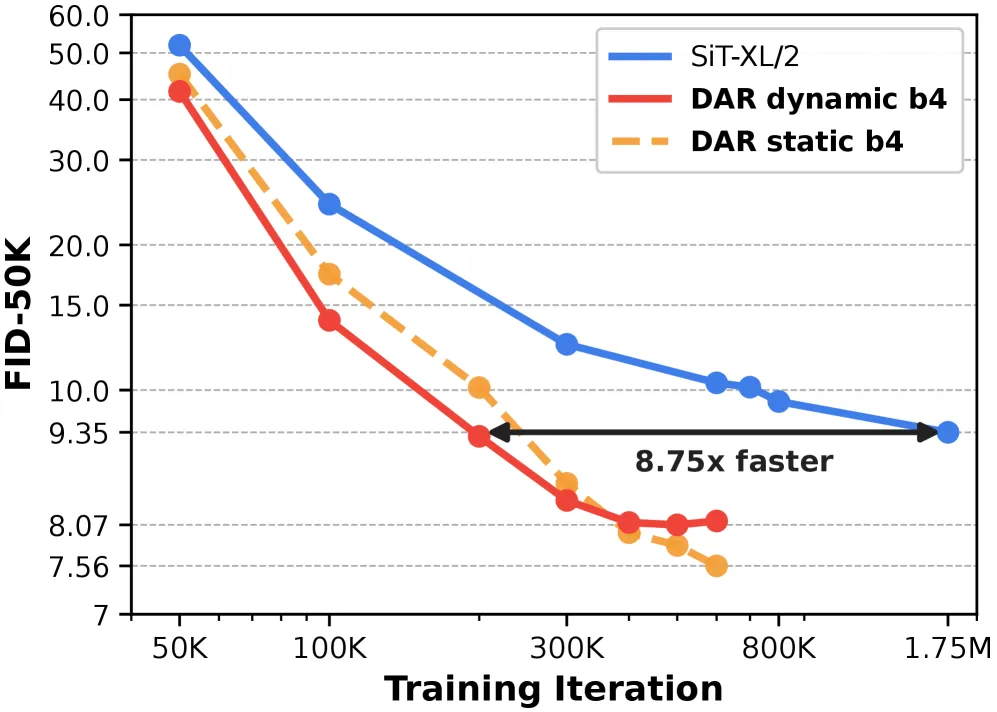
DAR 用随时间步自适应的子层输出聚合替换扩散 Transformer 的残差相加:SiT-XL/2 的 ImageNet FID 从 9.67 降到 7.56,迭代量仅基线 1/8.75。
快速答案
扩散自适应路由(Diffusion-Adaptive Routing,DAR)把扩散 Transformer 内部的普通残差相加,换成对历史子层输出的「可学习、随时间步自适应」加权聚合。在 ImageNet 256x256 上,它把 SiT-XL/2 的 FID 从 9.67 降到 7.56(提升 2.11 点),并用 8.75 倍更少的训练迭代追平基线的最终质量;叠在 REPA 之上还能在训练早期带来约 2 倍加速。
残差相加的三个毛病
这篇论文的贡献先是诊断,其次才是架构。标准残差连接 x = x + sublayer(x) 是从语言 Transformer 照搬来的,从未针对扩散重新审视过。作者在 SiT-XL/2 的 28 个 block 上,随深度增长测出三个具体病症:
- 前向幅值单调膨胀。 每个 block 只会往主干流里「加」,残差范数随深度稳步攀升;PreNorm 不得不去除越来越大的幅值,从而稀释了每个新 block 的贡献——越深的 block,实际能改动的越少。
- 反向梯度急剧衰减。 同样的累加,在反向传播里让早期层「挨饿」:传到底层的梯度迅速变小,网络底部训练得很弱。
- block 间显著冗余。 相邻 block 最终算出近乎重复的更新,浪费了一个 28 层模型本该用来学不同特征的容量。
需要诚实地说:单看每一条,在 Transformer 研究里都不算全新;新的是论文指出它们在扩散场景中尤其有害,而且一个机制就能同时治这三样。
DAR 怎么工作
DAR 不把每个子层的输出直接加进主干流,而是保留子层输出的历史,把下一层的输入构造成这些历史的可学习加权组合。两点关键。其一,聚合是非增量的:某个 block 可以下调甚至跳过早期贡献,而不必被迫扛着它们累积的幅值往前走——这直接打中了膨胀问题。其二,路由权重是随时间步自适应的:扩散在多个噪声水平上复用同一网络,DAR 让高噪声的早期步与接近干净的后期步用不同的路由,这是静态残差做不到的。
论文同时给出静态变体(固定的可学习系数,如 static c4 / static b4 配置)和随时间步条件化的动态变体。静态版尤其值得注意:它几乎不增加推理成本,却仍拿下了头条 FID 提升,是更易部署的那个结果。
关键结果
- ImageNet 256x256 FID: 静态配置下,DAR 把 SiT-XL/2 从 9.67 降到 7.56,提升 2.11 点。
- 训练效率: DAR 用 8.75 倍更少的训练迭代,追平 SiT-XL/2 基线收敛后的质量——这是核心效率主张,也是 FID-迭代曲线上标注的数字。
- 与 REPA 可叠加: 把 DAR 叠在 REPA 配方上,训练早期约有 2 倍加速,说明这一增益与表示对齐技巧正交,而非重叠。
- 通用性: 作者把 DAR 用于预训练、文生图微调与分布匹配蒸馏(DMD),论证这一路由修复不绑定单一训练范式。
为什么值得关注
8.75 倍迭代缩减,是这篇论文配得上一席之地的那个数字。扩散 Transformer 预训练被算力主导,而一个对残差路径的即插即用改动——不是新损失、新数据集或新采样器——能更早达到同样的 FID,正是实验室无需重构管线就能采纳的那类效率红利。对工程师来说,静态变体比动态版更重要,恰恰因为它在推理时几乎免费。把这个结果当作「DiT 式模型的残差连接从未为扩散调过」的证据,而不是某个新的图像生成 SOTA 主张。
局限与存疑
最强的结果集中在 SiT-XL/2、ImageNet 256x256、以 FID 为指标;FID 奖励分布匹配,可能在感知质量没明显变化时也会移动,所以这一增益需要在更高分辨率、以及文生图场景下的人类偏好上再确认。相比单条加法主干流,存储并在子层输出历史上做路由会增加显存与簿记开销;论文的叙述强调的是静态变体成本低——动态、随时间步条件化版本的开销才是要细究的地方。「8.75 倍更少迭代」是训练早中期的对比,这一优势能否一路保持到完全收敛的更长训练、能否迁移到 SiT 以外的架构,头条曲线并未给出定论。
常见问题
扩散自适应路由 DAR 是什么?
DAR 是对扩散 Transformer 里残差相加的替换。它不把每个子层的输出加进单一主干流,而是把每个 block 的输入构造成对此前所有子层输出的「可学习、随时间步自适应」加权组合,让各 block 能选择性复用或丢弃早期特征。
DAR 把扩散 Transformer 的质量提升了多少?
在 ImageNet 256x256 上,DAR 把 SiT-XL/2 的 FID 从 9.67 降到 7.56,提升 2.11 点,并用 8.75 倍更少的训练迭代追平基线收敛后的质量。
为什么标准残差连接会拖累扩散 Transformer?
论文测出三个随深度恶化的问题:前向幅值膨胀,在 PreNorm 下稀释更深的 block;反向梯度急剧衰减,使早期层训练不足;以及 block 间冗余,相邻 block 算出近乎重复的更新。
DAR 能配合 REPA 等训练方案吗?
能。叠在 REPA 上训练早期约有 2 倍加速;作者还把它用于文生图微调与分布匹配蒸馏,表明这一路由修复与这些方法基本正交。
一句话:扩散 Transformer 里的残差相加是语言模型的遗留物,换成随时间步自适应的路由,就能更便宜地买到大部分同样的图像质量。阅读 arXiv 原文。