Stream-T1:用测试时扩展提升流式视频生成
Stream-T1 不重训,只在推理时搜索,就把 5 秒片段的 VideoAlign 运动质量从 0.350 提到 0.629,并压住毁掉 30 秒长片的漂移。
快速答案
Stream-T1 让自回归流式视频模型不重训、只在推理时搜索,就能生成更长、更稳的片段。在 5 秒片段上,它把 VideoAlign 运动质量从 0.350 提到 0.629、视频质量从 0.285 提到 0.426(基线为 LongLive),VBench 美学质量从 65.28 升到 65.98。收益最大的是 30 秒长片:基线运动质量几乎为零(-0.002),Stream-T1 提到 0.226——而这正是流式模型通常崩掉的区间。
流式视频模型的痛点
流式视频生成是一块一块(chunk)地出片,每块通过 KV 缓存以前面的块为条件。这让它能实时运行、理论上生成任意长的视频,但弱点也在这里:误差会累积。第三块里的一点瑕疵会带偏第四块,主体慢慢变形、背景漂移,到 30 秒画面已肉眼可见地退化。常见解法是继续训练——更好的数据、更长的上下文、对生成器做 RL。Stream-T1 拒绝走这条路,改问一个不同的问题:给定一个冻结的流式模型,只在测试时多花算力做搜索,能把质量买回来多少?
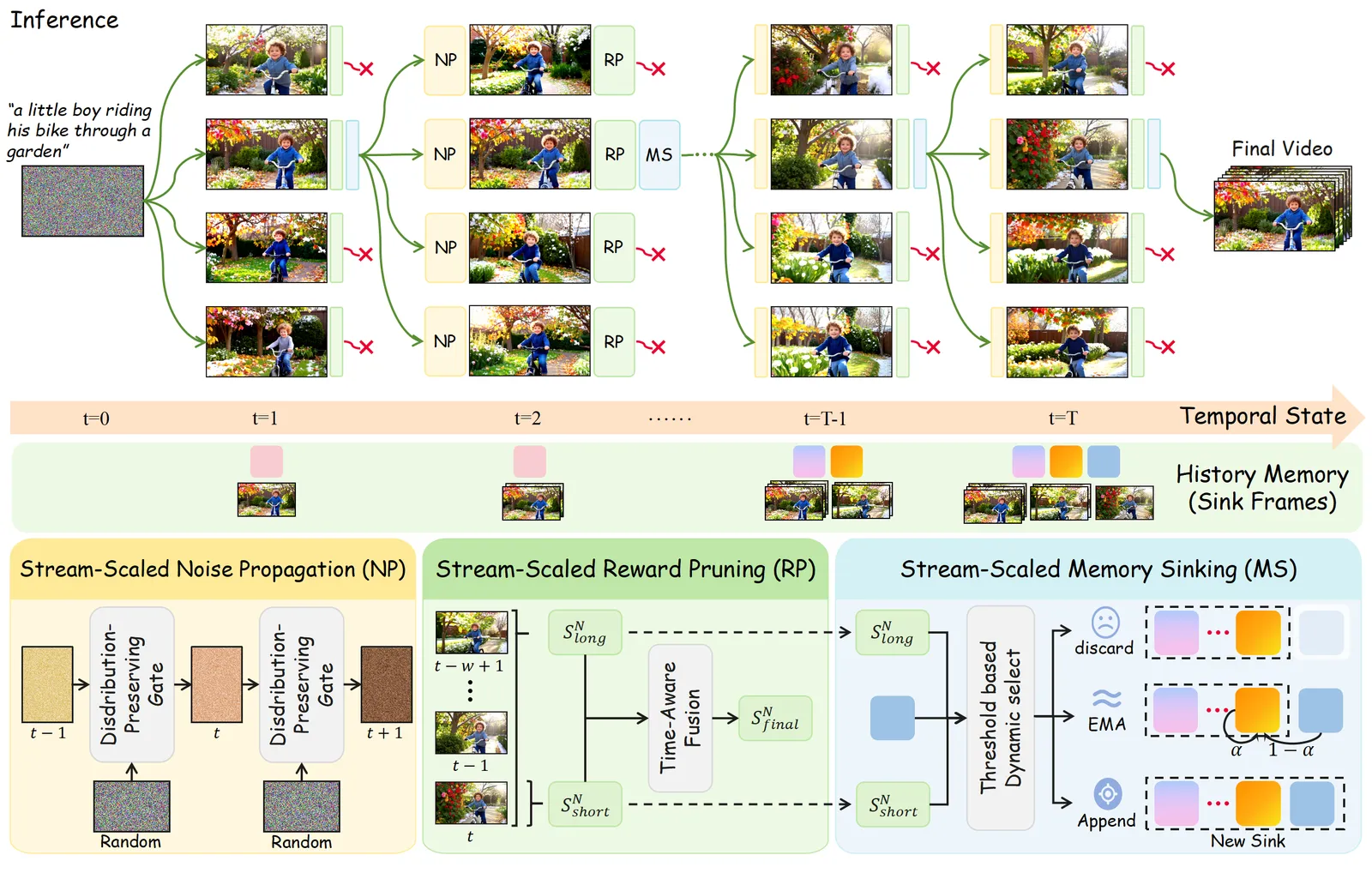
Stream-T1 怎么在推理时搜索
方法在块级别跑三招协同操作,全程免训练。
流式缩放噪声传播:每个新块的隐变量不再重新采样噪声,而是对前一块的噪声做球面插值来初始化。一个插值系数(取值 -1 到 1)控制前一块轨迹的延续强度,从而让运动连续,而不是每块都重启。
流式缩放奖励剪枝:这是测试时扩展的核心。Stream-T1 对每个块展开多个候选续写,再用组合分数剪枝——来自图像奖励的「短分」管单帧质量,来自视频奖励、在 10 块滑动窗口上计算的「长分」管时间连贯性。一个动态阈值随片段变长在两者间调权重,所以早期块偏重单帧质量、后期块偏重与历史保持一致。
流式缩放记忆下沉:决定从窗口(大小 9,注意力 sink 大小 3)里被淘汰的 KV 缓存怎么处理。它不一味丢弃,而是检测语义边界,把被淘汰的上下文导向三条路之一——丢弃、EMA 平滑下沉、或直接追加——让模型保住有用的长期记忆,又不让陈旧上下文污染新帧。
说句实话:这本质上是对视频块做束搜索,配上视频专用的打分和记忆处理,而不是一个新生成器。但这恰恰是它有意思的地方——任何流式模型都能套上这层壳。
关键结果
以下数字均来自论文的两个基准:5 秒用 946 条 VBench 提示词,30 秒用 128 条 MovieGen 提示词,16 FPS,832x480,基线 LongLive。
- 5 秒运动质量: VideoAlign MQ 从 0.350 升到 0.629;视频质量(VQ)从 0.285 到 0.426;文本对齐(TA)从 1.193 到 1.305。
- 30 秒运动质量: VideoAlign MQ 从 -0.002 到 0.226,VQ 从 -0.169 到 -0.073——正是该方法针对的长片漂移。
- 30 秒 VBench: 主体一致性 97.90 到 98.43,运动平滑度 98.78 到 99.03,美学质量 61.56 到 62.11。
- 5 秒 VBench: 表面指标几乎不动(运动平滑度 99.12 到 99.15,主体一致性 97.00 到 97.25),这反而是更值得玩味的结果——见下文。
怎样诚实地读这些数字
VideoAlign 涨幅很大、VBench 涨幅极小,这个反差才是真正的故事。VBench 的一致性、平滑度指标在基线上已是 97-99,几乎没有上升空间——运动平滑度 +0.03 是噪声,不是进步。真正能反映观感质量与对齐的奖励模型指标(VideoAlign)才是 Stream-T1 发力处:5 秒运动质量绝对值约 +0.28。所以 VBench 那张表该读成「没把已经好的东西弄坏」,VideoAlign 那张表才是真正的胜利。相对涨幅最大的出现在 30 秒,恰恰因为那是冻结基线在崩的地方。
局限与存疑
测试时搜索不是免费的。每块展开并打分多个候选会成倍增加推理算力,而论文的定位是实时流式——「多搜候选」与「保持实时」之间存在张力,光看收益并不能化解。提升也只在单一基线(LongLive)、两个基准上报告;这套噪声/奖励/记忆配方能否迁移到其它流式骨干、能否撑过 30 秒和超过 832x480,这里都未证明。而且收益骑在奖励模型上,就继承了它们的盲点:把 VideoAlign 优化到极致,可能漂向「奖励模型喜欢的」而非「看起来对的」,这正是奖励剪枝没能完全摆脱的失败模式。几个旋钮(插值系数、EMA 衰减、动态阈值)都是超参,大概率要按模型逐一调。
常见问题
Stream-T1 一句话是什么?
Stream-T1 是一个免训练的测试时扩展框架,它包住一个冻结的流式视频生成器,用块级搜索——噪声传播、奖励剪枝、记忆下沉——生成更长、更稳的片段。
Stream-T1 到底把质量提升了多少?
在 5 秒片段上,相对 LongLive 把 VideoAlign 运动质量从 0.350 提到 0.629、视频质量从 0.285 提到 0.426。标准 VBench 一致性指标只小幅变动,因为它们已在 97-99 接近饱和。
Stream-T1 需要重训视频模型吗?
不需要。Stream-T1 在推理时多花算力,而非训练。它把生成器当作冻结对象,只在候选块之间搜索,因此原则上能架在不同的流式模型之上。
为什么 Stream-T1 对 30 秒视频帮助更大?
流式模型的误差随时间累积,所以 30 秒片段比 5 秒漂移得严重得多。Stream-T1 的奖励剪枝和记忆下沉直接对抗这种漂移,因此它的相对收益——运动质量从约等于零提到 0.226——在长片上最大。
Stream-T1 有什么代价?
每块搜索多个候选会抬高推理成本;收益只在单一基线、两个基准上展示;依赖奖励模型还有「为打分器而优化、而非为真实观感而优化」的风险。
一句话:Stream-T1 表明流式视频模型留着真实的提升空间,纯测试时搜索就能把它捞回来——长片漂移处收益最大。阅读 arXiv 原文。