Multimodal Models · Retrieval-Augmented Generation
CiteVQA: A Benchmark That Catches Document AI Citing the Wrong Evidence
CiteVQA makes document QA models return bounding-box citations with every answer. The top model scores 76.0 Strict Attributed Accuracy; the best open model just 22.5 — most answer right but cite the wrong region.
Quick answer
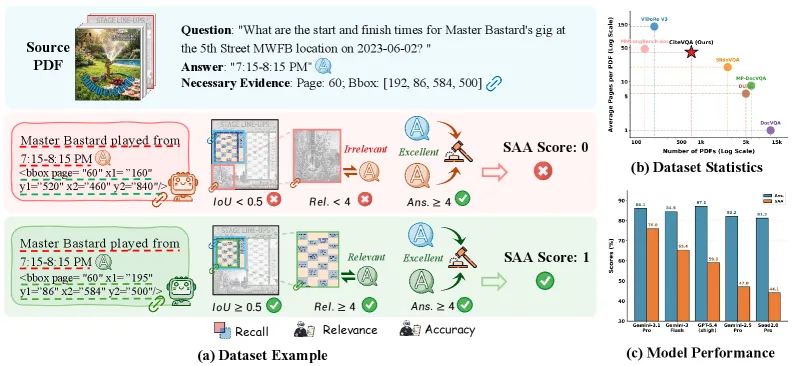
CiteVQA is a document-QA benchmark that refuses to grade the answer alone — a model must also return the bounding boxes of the evidence it used, and both are scored together. On its headline metric, Strict Attributed Accuracy (SAA), the best system tested, Gemini-3.1-Pro-Preview, reaches just 76.0, and the strongest open-source model, Qwen3-VL-235B-A22B, manages only 22.5. The gap exposes what the authors call “attribution hallucination”: models routinely give the right textual answer while pointing at the wrong part of the page.
Why answer-only scoring hides a real failure
Most document-QA benchmarks ask a question about a PDF and check whether the final text answer matches. That setup rewards a model that guesses correctly for the wrong reasons. In high-stakes document work — contracts, financial filings, medical records — a correct answer with no verifiable source is not trustworthy, because a reviewer cannot confirm it without re-reading the whole document. CiteVQA’s premise is that for trustworthy document intelligence, where the answer came from matters as much as the answer itself. So it requires element-level bounding-box citations alongside each answer and evaluates them jointly, turning “show your work” from a nice-to-have into a graded requirement.
What is in the benchmark
CiteVQA contains 1,897 questions over 711 PDFs spanning seven macro-domains (30 sub-categories) in two languages, English (451 docs) and Chinese (260 docs). The documents are long and realistic: 40.6 pages on average, median 30.0 — far closer to real filings than the single-page or short-document setups common in earlier VQA work. The questions are split by sourcing difficulty: 52.0% are single-document, 25.7% are multi-document with one gold source, and 22.3% are multi-document requiring evidence from several gold sources. That last slice is the hard case, where a model must locate and combine evidence scattered across pages and files rather than reading off one passage.
How CiteVQA scores grounding, not just answers
The benchmark defines four metrics. Recall measures whether the model’s cited boxes actually overlap the gold evidence regions at IoU greater than or equal to 0.5. Relevance is an LLM-judged 0-5 score for whether the cited evidence supports the answer. Answer Correctness is a separate LLM-judged 0-5 semantic match against the reference answer. The headline number, Strict Attributed Accuracy, is a sample-level binary: a sample counts only if the model both answers correctly and grounds that answer in the right evidence. SAA is deliberately unforgiving — it is the metric that collapses when a model is right by luck rather than by reading.
Key results
- Gemini-3.1-Pro-Preview tops the board at 76.0 SAA — the only model that clears three-quarters, and still a long way from solved.
- The best open-source model, Qwen3-VL-235B-A22B, scores 22.5 SAA, a roughly 53-point gap behind the leading closed model despite its size.
- 20 MLLMs were audited — 7 closed-source, 8 open-source large, and 5 open-source small — so the gap is a pattern across the field, not one weak entrant.
- Attribution hallucination is the central finding: models frequently produce a correct answer while citing entirely incorrect visual evidence, which is exactly the failure SAA is built to catch and answer-only benchmarks miss.
- Documents average 40.6 pages, so the localization task is genuinely hard — the evidence is a small region inside a long, multi-page PDF.
Why this matters now
Document AI is being sold into law, finance, and healthcare on the promise of “grounded” answers with citations. CiteVQA is the first benchmark I have seen that treats the citation as a first-class, jointly-scored output rather than a UI afterthought — and the result is sobering. A 76.0 ceiling from a frontier model, and 22.5 from the best open model, means the citation boxes these products show users are often wrong even when the answer is right. That is a worse failure mode than a wrong answer, because a confident, well-formatted, incorrect citation actively misleads a reviewer who trusts it.
Limits and open questions
CiteVQA is a benchmark paper, not a method: it diagnoses attribution hallucination but offers no model that fixes it, so the next step — training or prompting models to ground reliably — is left open. At 1,897 questions over 711 PDFs it is a focused diagnostic rather than a large training corpus, and the two-language, seven-domain scope, while broad for the genre, is not exhaustive. Two metrics (Relevance and Answer Correctness) rely on an LLM judge, which carries the usual risks of judge bias and inconsistency. And the IoU greater than or equal to 0.5 recall threshold is a design choice — a stricter bar would lower every score, so the absolute numbers are best read as relative rankings, not a fixed scale.
FAQ
What does CiteVQA actually measure?
CiteVQA measures whether a document-QA model can both answer a question correctly and cite the exact bounding boxes of the evidence it used, scored together. Its headline metric, Strict Attributed Accuracy, counts a sample only when the answer is correct and grounded in the right region.
Why is CiteVQA harder than normal document VQA?
Because answer-only benchmarks let a model pass by guessing right, while CiteVQA also checks the cited evidence boxes at IoU greater than or equal to 0.5. The documents average 40.6 pages, so finding the right region in a long PDF is part of the difficulty.
What is attribution hallucination in CiteVQA?
Attribution hallucination is when a model gives the correct textual answer but cites the wrong visual evidence. CiteVQA’s results show this is widespread, which is why top scores on Strict Attributed Accuracy stay far below answer-only accuracy.
How well do current models do on CiteVQA?
The best model, Gemini-3.1-Pro-Preview, reaches 76.0 Strict Attributed Accuracy, while the strongest open-source model, Qwen3-VL-235B-A22B, scores 22.5 across the 20 MLLMs evaluated. No model is close to solving grounded document QA.
One line: a correct answer with the wrong citation is still a failure, and CiteVQA is the first benchmark that grades it that way. Read the original paper on arXiv.