Language Models · LLM Reasoning
TransitLM: A Map-Free Transit Routing Dataset and Benchmark
TransitLM is a 13M-record corpus from four Chinese cities (120,845 stations) that trains a language model to plan transit routes with no map engine — a 4B model hits 97.0% connectivity and 71.0% exact match.
Quick answer
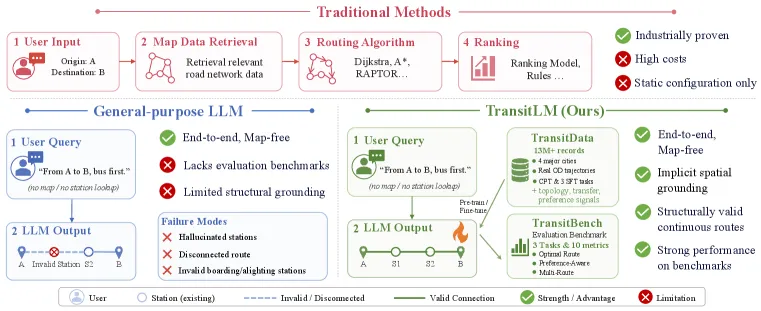
TransitLM is a dataset and benchmark that tests whether a language model can plan public-transit routes without a routing engine or structured map — just by reading origin and destination text and emitting a station-by-station route. It contains over 13 million route-planning records from four Chinese cities, covering 120,845 stations and 13,666 lines. After domain-adaptive continual pre-training plus supervised fine-tuning, a 4B Qwen3 model reaches 97.0% connectivity and 71.0% route-exact-match on the optimal-route task — far above general-purpose LLMs prompted on the same problem.
The problem: transit planning is locked to map infrastructure
Every transit app today sits on top of a routing engine and a structured graph of stations, lines, and timetables. That stack is expensive to build and maintain, and it does not exist in a form a language model can simply learn from. The authors’ framing is sharper than “let’s try an LLM on maps”: there is no public dataset that lets you train a model to bypass the routing engine at all. TransitLM is built to fill that gap, and the “map-free” label is the whole point — the model is never given an explicit graph; it has to absorb the city’s topology from raw planning records.
What is in the dataset
The corpus is 13M+ records drawn from Beijing, Shanghai, Shenzhen, and Chengdu — 120,845 stations and 13,666 lines in total. It ships in two roles: a continual pre-training corpus, and labeled benchmark data for three evaluation tasks:
- Optimal route generation — produce the single best route for an origin-destination pair.
- Preference-aware planning — honor an explicit preference such as subway-first, bus-first, fewer transfers, or shortest time.
- Multi-route generation — return three diverse routes for the same pair.
One design choice matters more than it looks: station IDs are registered as dedicated tokens. That stops the model from spelling station names character-by-character and hallucinating stops that do not exist — the most obvious failure mode when an LLM emits a route as free text.
How the evaluation actually works
A route is not graded by string match alone, which is the honest part of this benchmark. The metric suite spans five families: connectivity (are consecutive stations actually reachable), access feasibility (station grounding and distance plausibility), route overlap (line overlap, station-sequence overlap, exact match), numeric-field accuracy (estimation accuracy and MAPE on quantities like time/distance), and task-specific scores (preference compliance, route diversity). This matters because a model can score well on exact match while still emitting physically impossible hops, so connectivity and grounding are the metrics that catch hallucinated geography.
Key results
- Optimal routing (4B Qwen3): 97.0% connectivity, 98.5% station grounding, 71.0% route exact match, 98.5% estimation accuracy, and 1.33% MAPE.
- Preference-aware planning: 93.2% connectivity, 50.4% exact match, and 89.8% preference compliance — the model usually honors the requested preference even when its route differs from the reference.
- Multi-route generation: 96.3% connectivity, 64.5% exact match, and 0.545 route diversity.
- Scale and baselines: the authors train Qwen3 at 0.6B, 1.7B, and 4B, and compare against six general-purpose LLMs including GPT-5.4-pro, DeepSeek-V4-Pro, Gemini-3.1-Pro, and Claude-Opus-4.6. The fine-tuned small models are the strong ones here — out-of-the-box frontier LLMs do not match a domain-trained 4B on these tasks.
The standout number is the gap between connectivity (97.0%) and exact match (71.0%) on optimal routing: the model almost always produces a valid, traversable route, but only matches the reference route about seven times in ten. For a planning system, “valid but not identical to the canonical answer” is often fine — there can be more than one good route — so exact match understates real usefulness.
Why this is interesting now
It is a clean test of whether spatial topology can live inside model weights instead of an external graph. If a 4B model can reconstruct reachable routes across 120k+ stations from text alone, that is evidence LLMs implicitly memorize structured geography at useful fidelity — and it hints at lighter on-device routing where shipping a full map engine is impractical. The bigger contribution is the benchmark: it gives the field a shared, metric-rich way to measure transit-route generation rather than each group reporting a custom score.
Limits and open questions
The honest caveats are stated by the authors. The dataset covers only four cities from a single platform, so generalization to other geographies, data sources, or smaller cities with sparse coverage is untested. It captures static route structure only — no real-time delays, service changes, or live crowding, which is exactly what makes production transit routing hard. And the headline scores are from the platform’s own reference routes, so 71.0% exact match measures agreement with one provider’s notion of “optimal,” not ground-truth optimality. Anyone hoping to drop a map engine should read this as a strong proof of concept, not a deployable replacement.
FAQ
What is TransitLM?
TransitLM is a large-scale dataset and benchmark for map-free transit route generation: 13M+ planning records from four Chinese cities (120,845 stations, 13,666 lines) used to train and evaluate language models that plan transit routes from text without a routing engine.
How well does TransitLM’s model plan routes?
A 4B Qwen3 model fine-tuned on TransitLM reaches 97.0% connectivity and 71.0% route exact match on optimal routing, plus 89.8% preference compliance on preference-aware planning — substantially better than general-purpose LLMs prompted on the same tasks.
What does “map-free” mean in TransitLM?
Map-free means the model is never given an explicit station/line graph or routing engine. It learns the city’s topology implicitly from raw planning records and emits routes directly, with station IDs registered as dedicated tokens to prevent hallucinated stops.
What are the limitations of TransitLM?
TransitLM covers only four Chinese cities from one platform and captures static route structure with no real-time dynamics. Its exact-match scores measure agreement with that platform’s reference routes rather than ground-truth optimality, so it is a proof of concept, not a production routing replacement.
One line: TransitLM shows a small fine-tuned LLM can reconstruct valid transit routes across 120k+ stations from text alone — read the original paper on arXiv.