Fine-Tuning & Adaptation · LLM Reasoning · Efficient AI
Trust-Region Behavior Blending: A Warmup Fix for On-Policy Distillation
On-policy distillation wastes teacher supervision on a student's weak early rollouts. TRB blends teacher-like behavior inside a KL trust region during warmup, then anneals it to zero — best average on two math settings.
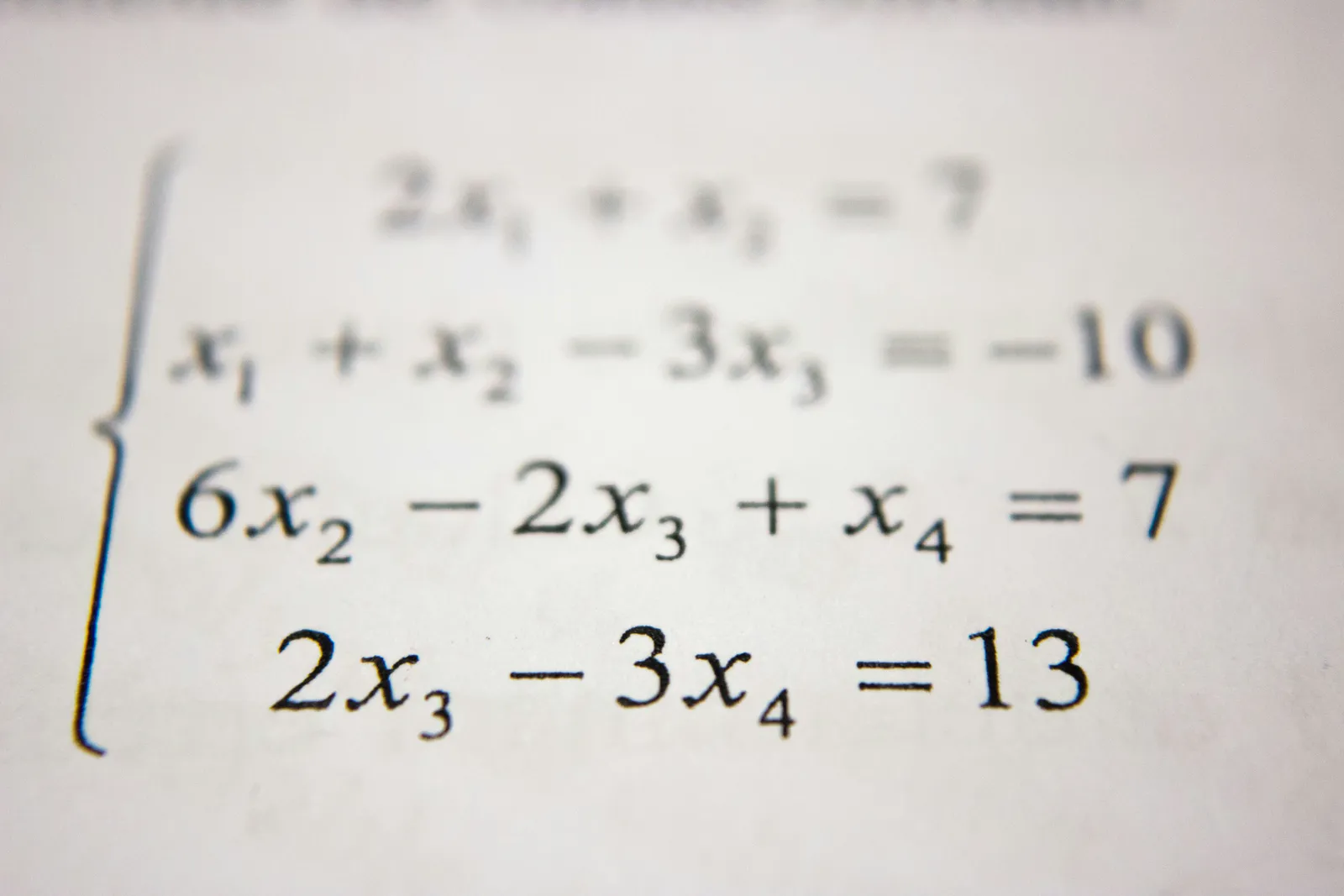
Quick answer
Trust-Region Behavior Blending (TRB) fixes a specific failure in on-policy distillation: early in training the student samples from a weak policy, so the teacher ends up correcting garbage prefixes that the student would never produce once it improves. TRB replaces those early rollouts with the closest-to-teacher behavior policy that still sits inside a student-centered KL trust region, keeps the same per-prefix reverse-KL distillation loss, and anneals the KL budget to zero so training collapses back to pure student rollouts after warmup. Across two math-reasoning distillation settings, TRB lands the strongest average among the methods compared.
The problem with on-policy distillation’s first steps
On-policy distillation (OPD) trains a student on prefixes it samples itself, then matches a stronger teacher’s next-token distribution on those prefixes. That design exists to kill the train/test mismatch of offline distillation, where the student only ever learns on teacher-generated text it will never see at inference. OPD is the right idea — but it has an ugly transient. At the start of training the student is bad, so its self-generated prefixes are low quality or off-distribution. The teacher then spends its supervision teaching the student how to continue prefixes that a competent student would never have written. It is wasted signal, and on hard tasks like math reasoning, where one bad early token derails a whole chain, it can be actively harmful.
The honest framing: this is a cold-start problem, the same class of problem that reasoning-model recipes solve with curated warmup data. TRB solves it without any extra data.
How TRB works
TRB changes only where the prefixes come from during warmup, not the loss. Three moving parts:
- A behavior policy, not the raw student. Instead of rolling out from the student, TRB rolls out from a blended behavior policy that leans toward the teacher’s outputs — so early prefixes are competent.
- A student-centered KL trust region. The behavior policy is not just “the teacher.” It is the closest-to-teacher policy that still stays within a bounded KL of the student. This keeps the prefixes on-distribution enough that the student can actually learn from them, instead of chasing a teacher it cannot yet imitate.
- A KL budget annealed to zero. The trust-region radius shrinks over training. As it hits zero the behavior policy becomes the student itself, so TRB smoothly hands control back to standard on-policy rollouts. The warmup leaves no permanent bias.
Critically, the per-prefix reverse-KL OPD objective is untouched. TRB is a rollout-side intervention bolted onto an existing OPD setup, not a new loss function. That is what makes it cheap to adopt.
Key results
- TRB attains the strongest average among the compared methods across two math-reasoning distillation settings — the headline claim, and a measured one: it is “strongest on average,” not a blowout on every benchmark.
- The win comes specifically from the warmup phase, where naive OPD wastes teacher supervision on poor student prefixes; TRB redirects that early budget toward teacher-quality prefixes.
- Because the KL budget anneals to zero, the late-training behavior is identical to standard OPD — so the gains are attributable to the warmup, not to a persistent change in the training distribution.
The paper does not report a single dramatic point gain the way a flagship model release would. Read it as a training-recipe refinement, not a new capability.
Why this matters now
Distillation is how the open ecosystem turns expensive frontier reasoning into small, cheap, deployable models, and on-policy distillation is the current best practice for doing it without train/test mismatch. The early-rollout problem is a real tax on every OPD run. TRB is attractive because it is a drop-in: it reuses the existing reverse-KL loss, needs no curated warmup dataset, and self-disables via annealing. For a team already running OPD on math or code, the cost of trying it is low.
Limits and open questions
The evidence base is narrow. “Strongest average across two math-reasoning settings” is a thin slate — math reasoning is exactly where verifiable structure and clean reward signals make many tricks look good. Whether TRB helps on open-ended generation, code, or multilingual distillation is untested here. The method also adds hyperparameters — the initial KL budget and the annealing schedule — and a warmup that is too aggressive or annealed too slowly could leave the student over-fit to teacher-like prefixes it cannot reproduce on its own. The paper does not provide public affiliations on the abstract page, and the “compared methods” set and exact benchmark numbers need the full PDF to evaluate. Treat the magnitude of the gain as unverified from the abstract alone.
FAQ
What does Trust-Region Behavior Blending (TRB) actually fix?
TRB fixes wasted teacher supervision at the start of on-policy distillation. Early student rollouts are low quality, so the teacher corrects prefixes the student would never generate once trained. TRB substitutes teacher-like behavior inside a KL trust region during warmup so the early supervision lands on competent prefixes.
How is TRB different from standard on-policy distillation?
Standard OPD always rolls out from the current student. TRB changes only the warmup rollout source — it samples from the closest-to-teacher policy within a bounded KL of the student — while keeping the same per-prefix reverse-KL loss. The KL budget anneals to zero, so TRB becomes plain OPD by the end of training.
Does TRB need extra training data?
No. TRB needs no curated cold-start dataset. It is a rollout-side modification that derives its behavior policy from the existing teacher and student, then disables itself via KL annealing.
How well does TRB perform on math reasoning?
TRB reports the strongest average among the compared methods across two math-reasoning distillation settings. It is framed as a best-on-average warmup improvement rather than a large single-benchmark jump.
One line: don’t make a strong teacher tutor a weak student on prefixes the student would never write — blend in teacher behavior inside a shrinking KL trust region, then get out of the way. Read the original paper on arXiv.